Intelligent Document Processing (IDP) revolutionizes the way businesses handle and interpret documents, leveraging advanced AI and machine learning technologies. It automates the extraction, understanding, and processing of data from a variety of document formats, transforming unstructured content into actionable insights. IDP enhances efficiency, accuracy, and decision-making, enabling organizations to focus on strategic growth and customer satisfaction.
What are the Business Benefits of IDP?
Intelligent Document Processing (IDP) offers transformative benefits by automating the extraction and interpretation of data across diverse document types. Key advantages include significant time savings through reduced manual data entry, enhanced accuracy with minimal error rates, and improved compliance with regulatory standards. Furthermore, IDP unlocks valuable insights from unstructured data, enabling better decision-making and driving operational efficiencies. This leads to streamlined workflows, cost reductions, and elevated customer experiences, positioning businesses for competitive advantage and growth.
Efficiency Enhancement
IDP can process large volumes of documents accurately and quickly, which leads to improved efficiency and reduced processing times. This eliminates the need for manual data entry and other repetitive tasks, which allows employees to focus on core functions that require human judgment and decision-making.
Accuracy Improvement
IDP uses technologies like OCR and AI to extract data from documents accurately. They reduce the risk of errors and ensure the extracted data is reliable and compliant with relevant regulations and standards. By automating data extraction and validation, IDP enhances the accuracy of document processing workflows, leading to better business results.
Cost Savings
By automating document process workflows, IDP reduces the need for manual intervention, leading to manual document processing costs and cost savings for businesses. This is because manual document processing costs are high due to the need for paper-based processing, manual data entry, and other repetitive tasks. IDP helps businesses to save money by automating these tasks and reducing the need for human involvement.
Enhanced Customer Service
IDP can help businesses improve customer service by reducing processing times and improving accuracy. This leads to faster processing of customer requests, better data quality, and improved customer satisfaction.
Scalability
IDP is scalable and can handle large volumes of data. This makes IDP ideal for businesses of all sizes, from small startups to large corporations. It can also be customized based on different business processes to meet specific needs, making it a versatile technology.
Better Compliance
IDP allows businesses to comply with relevant regulations and standards by ensuring that the extracted data is accurate and compliant. This reduces the risk of penalties and fines and helps companies to maintain a good reputation with customers and regulatory bodies.
Automating Documents for your Industry
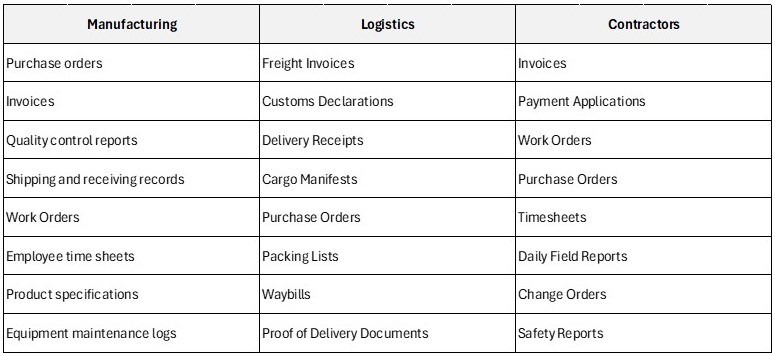
Some examples of documents that can be processing with Intelligent Document Processing (IDP)
Turn your documents bottlenecks into breakthroughs
Embracing IDP in your industry is not just a technological upgrade, it’s a strategic move toward efficiency, accuracy, and competitiveness. Hi Automation helps you automate crucial documents that save time and resources and position your company at the forefront of revolutionary growth. As all industries continue their digital journey, IDP stands as a beacon, illuminating the path toward a future where data is managed and harnessed for unparalleled growth and success.
Artificial Intelligence is hot. We can hardly do anything without coming into contact, consciously or unconsciously, with forms of Artificial Intelligence. And it is becoming increasingly important. This article is an introduction to the field of Artificial Intelligence. It starts with a definition and then explores the different sub-specialties, complete with description and some applications.
WHAT IS ARTIFICIAL INTELLIGENCE?
Artificial Intelligence (AI) uses computers and machines to imitate people’s problem-solving and decision-making skills. One of the leading textbooks in the field of AI is Artificial Intelligence: A Modern Approach (link resides outside Axisto) by Stuart Russell and Peter Norvig. In it they elaborate four possible goals or definitions of AI.
Human approach:
Systems that think like people
Systems that behave like people
Rational approach:
Systems that think rationally
Systems that act rationally
Artificial intelligence plays a growing role in (I)IoT (Industrial) Internet of Things, among others), where (I)IoT platform software can provide integrated AI capabilities.
SUB-SPECIALTIES WITHIN ARTIFICIAL INTELLIGENCE
There are several subspecialties that belong to the domain of Artificial Intelligence. While there is some interdependence between many of these specialties, each has unique characteristics that contribute to the overarching theme of AI. The Intelligent Automation Network (link resides outside Axisto) distinguishes seven subspecialties, figure 1.
Figure 1, The Intelligent Automation Network distinguishes seven subspecialities within Artificial Intelligenge
Each subspecialty is further explained below.
MACHINE LEARNING
Machine learning is the field that focuses on using data and algorithms to imitate the way humans learn using computers, without being explicitly programmed, while gradually improving accuracy. The article “Axisto – an introduction to Machine Learning” takes a closer look at this specialty.
MACHINE LEARNING AND PREDICTIVE ANALYTICS
Predictive analytics and machine learning go hand in hand. Predictive analytics encompasses a variety of statistical techniques, including machine learning algorithms. Statistical techniques analyse current and historical facts to make predictions about future or otherwise unknown events. These predictive analytics models can be trained over time to respond to new data.
The defining functional aspect of these engineering approaches is that predictive analytics provides a predictive score (a probability) for each “individual” (customer, employee, patient, product SKU, vehicle, part, machine, or other organisational unit) to determine, to inform or influence organisational processes involving large numbers of “individuals”. Applications can be found in, for example, marketing, credit risk assessment, fraud detection, manufacturing, healthcare and government activities, including law enforcement.
Unlike other Business Intelligence (BI) technologies, predictive analytics is forward-looking. Past events are used to anticipate the future. Often the unknown event is of significance in the future, but predictive analytics can be applied to any type of “unknown,” be it past, present, or future. For example, identifying suspects after a crime has been committed, or credit card fraud if it occurs. The core of predictive analytics is based on capturing relationships between explanatory variables and the predicted variables from past events, and exploiting them to predict the unknown outcome. Of course, the accuracy and usefulness of the results strongly depends on the level of data analysis and the quality of the assumptions.
Machine Learning and predictive analytics can make a significant contribution to any organisation, but implementation without thinking about how they fit into day-to-day operations will severely limit their ability to deliver relevant insights.
To extract value from predictive analytics and machine learning, it’s not just the architecture that needs to be in place to support these solutions. High-quality data must also be available to nurture them and help them learn. Data preparation and quality are important factors for predictive analytics. Input data can span multiple platforms and contain multiple big data sources. To be usable, they must be centralised, unified and in a coherent format.
To this end, organisations must develop a robust approach to monitor data governance and ensure that only high-quality data is captured and stored. Furthermore, existing processes need to be adapted to include predictive analytics and machine learning as this will enable organisations to improve efficiency at every point in the business. Finally, they need to know what problems they want to solve in order to determine the best and most appropriate model.
NATURAL LANGUAGE PROCESSING (NLP)
Natural language processing is the ability of a computer program to understand human language as it is spoken and written – also known as natural language. NLP is a way for computers to analyse and extract meaning from human language so that they can perform tasks such as translation, sentiment analysis, and speech recognition.
This is difficult, as it involves a lot of unstructured data. The style in which people speak and write (“tone of voice”) is unique to individuals and is constantly evolving to reflect popular language use. Understanding context is also a problem – something that requires semantic analysis from machine learning. Natural Language Understanding (NLU) is a branch of NLP and picks up these nuances through machine “reading understanding” rather than simply understanding the literal meanings. The purpose of NLP and NLU is to help computers understand human language well enough so that they can converse naturally.
All these functions get better the more we write, speak and talk to computers: they are constantly learning. A good example of this iterative learning is a feature like Google Translate that uses a system called Google Neural Machine Translation (GNMT). GNMT is a system that works with a large artificial neural network to translate more smoothly and accurately. Instead of translating one piece of text at a time, GNMT tries to translate entire sentences. Because it searches millions of examples, GNMT uses a broader context to derive the most relevant translation.
The following is a selection of tasks in natural language processing (NLP). Some of these tasks have direct real-world applications, while others more often serve as sub-tasks used to solve larger tasks.
Optical Character Recognition (OCR)
Determining the text associated with a given image representing printed text.
Speech Recognition
Determine the textual representation of the speech on the basis of a sound fragment of a speaking person or persons. This is the opposite of text-to-speech and is an extremely difficult problem. In natural speech, there are hardly any pauses between consecutive words, so speech segmentation is a necessary subtask of speech recognition (see ‘word segmentation below). In most spoken languages, the sounds representing successive letters merge into one another in a process called coarticulation. Thus, the conversion of the analog signal to discrete characters can be a very difficult process. Since words are spoken in the same language by people with different accents, the speech recognition software must also be able to recognise a wide variety of inputs as identical to each other in terms of textual equivalents.
Text-to-Speech
The elements of a given text are transformed and a spoken representation is produced. Text-to-speech can be used to help the visually impaired.
Word Segmentation (Tokenization)
Splitting a piece of continuous text into individual words. For a language like English, this is quite trivial, as words are usually separated by spaces. However, some written languages such as Chinese, Japanese, and Thai do not mark word boundaries in such a way, and in those languages, text segmentation is an important task that requires knowledge of the vocabulary and morphology of words in the language. Sometimes word segmentation is also applied in, for example, making words in data mining.
Document AI
A Document AI platform sits on top of NLP technology, allowing users with no previous experience with artificial intelligence, machine learning, or NLP to quickly train a computer to extract the specific data they need from different document types. NLP-powered Document AI enables non-technical teams to quickly access information hidden in documents, e.g. lawyers, business analysts and accountants.
Grammatical Error Correction
Grammatical error detection and correction involves a wide range of problems at all levels of linguistic analysis (phonology/orthography, morphology, syntax, semantics, pragmatics). Grammatical error correction has a major impact because it affects hundreds of millions of people who use or learn a second language. In terms of spelling, morphology, syntax, and certain aspects of semantics, with the development of powerful neural language models such as GPT-2, this can be regarded as a largely solved problem since 2019. Various commercial applications are available in the market.
Machine Translation
Automatically translating text from one human language to another is one of the most difficult problems: all different kinds of knowledge are required to do it properly, such as grammar, semantics, real world facts, etc..
Natural Language Generation (NLG)
Converting information from computer databases or semantic intent into human readable language.
Natural Language Understanding (NLU)
NLU concerns the understanding of human language, such as Dutch, English, and French, which allows computers to understand commands without the formalised syntax of computer languages. NLU also allows computers to communicate back to people in their own language. The main goal of NLU is to create chat and voice-enabled bots that can communicate with the public unsupervised. Answer questions and determine the answer to a question in human language. Typical questions have a specific correct answer, such as “What is the capital of Finland?”, but sometimes open questions are also considered (such as “What is the meaning of life?”). How does understanding natural language work? NLU analyses data to determine its meaning by using algorithms to reduce human speech to a structured ontology – a data model made up of semantics and pragmatic definitions. Two fundamental concepts of NLU are intent and entity recognition. Intent recognition is the process of identifying user sentiment in input text and determining its purpose. This is the first and most important part of NLU as it captures the meaning of the text. Entity Recognition is a specific type of NLU that focuses on identifying the entities in a message and then extracting key information about those entities. There are two types of entities: named entities and numeric entities. Named entities are grouped into categories, such as people, businesses, and locations. Numeric entities are recognised as numbers, currency and percentages.
Text-to-picture generation
Describe an image and generate an image that matches the description.
Natural language processing – understanding people – is key to AI justifying its claim to intelligence. New deep learning models are constantly improving the performance of AI in Turing tests. Google’s Director of Engineering Ray Kurzweil predicts AIs will “reach human levels of intelligence by 2029“(link resides outside Axisto).
By the way, what people say is sometimes very different from what people do. Understanding human nature is by no means easy. More intelligent AIs expand the perspective of artificial consciousness, opening up a new field of philosophical and applied research.
SPEECH
Speech recognition is also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text. It is a capability that uses natural language processing (NLP) to process human speech in a written format. Many mobile devices incorporate speech recognition into their systems to perform voice searches, e.g. Siri from Apple.
An important area of speech in AI is speech-to-text, the process of converting audio and speech into written text. It can help visually or physically impaired users and can promote safety with hands-free operation. Speech-to-text tasks contain machine learning algorithms that learn from large datasets of human voice samples to arrive at adequate usability quality. Speech-to-text has value for businesses because it can help transcribe video or phone calls. Text-to-speech converts written text into audio that sounds like natural speech. These technologies can be used to help people with speech disorders. Polly from Amazon is an example of a technology that uses deep learning to synthesise human-sounding speech for the purposes of e-learning and telephony, for example.
Speech recognition is a task where speech is received by a system through a microphone and checked against a database of large pattern recognition vocabulary. When a word or phrase is recognised, it will respond with the corresponding verbal response or a specific task. Examples of speech recognition include Apple’s Siri, Amazon’s Alexa, Microsoft’s Cortana, and Google’s Google Assistant. These products must be able to recognise a user’s speech input and assign the correct speech output or action. Even more sophisticated are attempts to create speech based on brain waves for those who cannot speak or have lost the ability to speak.
EXPERT SYSTEMS
An expert system uses a knowledge base about its application domain and an inference engine to solve problems that normally require human intelligence. An interference engine is a part of the system that applies logical rules to the knowledge base to derive new information. Examples of expert systems include financial management, business planning, credit authorisation, computer installation design, and airline planning. For example, an expert traffic management system can help design smart cities by acting as a “human operator” to relay traffic feedback for appropriate routes.
A limitation of expert systems is that they lack the common sense people have, such as an understanding of the limits of their skills and how their recommendations fit into the bigger picture. They lack the self-awareness of people. Expert systems are not a substitute for decision makers because they lack human capabilities, but they can dramatically ease the human work required to solve a problem.
PLANNING SCHEDULING AND OPTIMALISATION
AI planning is the task of determining how a system can best achieve its goals. It is choosing sequential actions that have a high probability of changing the state of the environment incrementally in order to achieve a goal. These types of solutions are often complex. In dynamic environments with constant change, they require frequent trial-and-error iteration to fine-tune.
Planning is making schedules, or temporary assignments of activities to resources, taking into account goals and constraints. To design an algorithm, planning determines the sequence and timing of actions generated by the algorithm. These are typically performed by intelligent agents, autonomous robots and unmanned vehicles. When designed properly, they can solve organisational scheduling problems in a cost-effective way. Optimisation can be achieved by using one of the most popular ML and Deep Learning optimisation strategies: gradient descent. This is used to train a machine learning model by changing its parameters in an iterative way to minimise a particular function to the local minimum.
Intelligence is at one end of the Intelligent Automation spectrum, while Robotic Process Automation (RPA), software robots that mimic human actions, is at the other end. One is concerned with replicating how people think and learn, while the other is concerned with replicating how people do things. Robotics develops complex sensor-motor functions that enable machines to adapt to their environment. Robots can sense the environment using computer vision.
The main idea of robotics is to make robots as autonomous as possible through learning. Despite not achieving human-like intelligence, there are still many successful examples of robots performing autonomous tasks such as carrying boxes, picking up and putting down objects. Some robots can learn decision making by associating an action with a desired outcome. Kismet, a robot at M.I.T.’s Artificial Intelligence Lab, learns to recognise both body language and voice and respond appropriately. This MIT video (link is outside Axisto) gives a good impression.
COMPUTER VISION
Computer vision is an area of AI that trains computers to capture and interpret information from image and video data. By applying machine learning (ML) models to images, computers can classify and respond to objects, such as facial recognition to unlock a smartphone or approve intended actions. When computer vision is coupled with Deep Learning, it combines the best of both worlds: optimised performance combined with accuracy and versatility. Deep Learning offers IoT developers greater accuracy in object classification.
Machine vision goes one step further by combining computer vision algorithms with image registration systems to better control robots. An example of computer vision is a computer that can “see” a unique series of stripes on a universal product code and scan it and recognize it as a unique identifier. Optical Character Recognition (OCR) uses image recognition of letters to decipher paper printed records and/or handwriting, despite the wide variety of fonts and handwriting variations.
WHAT IS MACHINE LEARNING?
This article covers the introduction to machine learning and the directly related concepts.
Machine learning is the field of study that gives computers the ability to learn without being explicitly programmed. It is a subset of artificial intelligence (AI) and computer science that focuses on the use of data and algorithms to imitate the way humans learn, and in doing so it gradually improving its accuracy. By using statistical learning (link resides outside Axisto) and optimisation methods, computers can analyse datasets and identify patterns in the data. Machine learning techniques leverage data mining to identify historic trends to inform future models.
According to the University of California, Berkeley, the typical supervised machine learning algorithm consists of three main components:
A decision process: A recipe of calculations or other steps that takes in the data and returns a guess at the kind of pattern in the data that the algorithm is looking to find.
An error function: A method of measuring how good the guess was by comparing it to known examples (when they are available). Did the decision process get it right? If not, how do you quantify how bad the miss was?
An updating or optimisation process: The algorithm looks at the miss and then updates how the decision process comes to the final decision so that the miss will not be as great the next time.
Machine learning is a key component in the growing field of data science. Using statistical methods, algorithms are trained to make classifications or predictions and uncover key insights from data.
HOW DOES A MACHINE LEARNING ALGORITHM LEARN?
The technology company Nvidia (link resides outside Axisto) distinguishes four learning models that are defined by the level of human intervention:
Supervised learning: If you are learning a task under supervision, someone is with you, prompting you and judging whether you’re getting the right answer. Supervised learning is similar in that it uses a full set of labelled* data to train an algorithm.
Unsupervised learning: In unsupervised learning, a deep learning model is handed a dataset without explicit instructions on what to do with it. The training dataset is a collection of examples without a specific desired outcome or correct answer. The neural network then attempts to automatically find structure in the data by extracting useful features and analysing its structure. It learns by looking for patterns.
Semi-supervised learning: Semi-supervised learning is, for the most part, just what it sounds like: a training dataset with both labelled and unlabelled data. This method is particularly useful in situations where extracting relevant features from the data is difficult or where labelling examples is a time-intensive task for experts.
Reinforcement learning: In this kind of machine learning, AI agents are trying to find the optimal way to accomplish a particular goal or improve the performance of a specific task. If the agent takes action that moves the outcome towards the goal, it receives a reward. To make its choices, the agent relies both on learnings from past feedback and on exploration of new tactics that may present a larger payoff. The overall aim is to predict the best next step that will earn the biggest final reward. Just as the best next move in a chess game may not help you eventually win the game, the best next move the agent can make may not result in the best final result. Instead, the agent considers the long-term strategy to maximise the cumulative reward. It is an iterative process: the more rounds of feedback, the better the agent’s strategy becomes. This technique is especially useful for training robots to make a series of decisions for tasks such as steering an autonomous vehicle or managing inventory in a warehouse.
* Fully labelled means that each example in the training dataset is tagged with the answer the algorithm should produce on its own. So a labelled dataset of flower images would tell the model which photos were of roses, daisies and daffodils. When shown a new image, the model compares it to the training examples to predict the correct label.
In all four learning models, the algorithm learns from datasets based on human rules or knowledge.
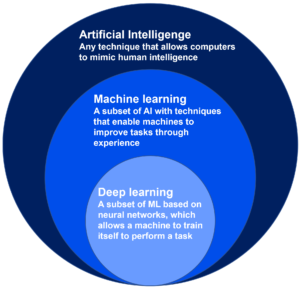
In the domain of artificial intelligence, you will come across the terms machine learning (ML), deep learning (DL) and neural networks (artificial neural networks – ANN). Artificial intelligence and machine learning are often used interchangeably, as are machine learning and deep learning. But, in fact, these terms are progressive subsets within the larger AI domain, as illustrated in Figure 1.
Figure 1. Artificial neural networks are a subset of deep learning, which is a subset of machine learning, which in turn is a subset of artificial intelligence.
Therefore, when discussing machine learning, we must also consider deep learning and artificial neural networks.
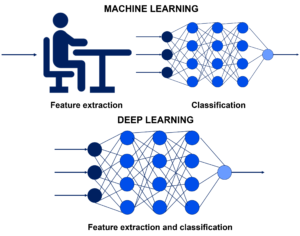
THE DIFFERENCE BETWEEN MACHINE LEARNING AND DEEP LEARNING IS THE WAY AN ALGORITHM LEARNS
Unlike machine learning, deep learning does not require human intervention to process data. Deep learning automates much of the feature extraction piece of the process, eliminating some of the manual human intervention required, which means it can be used for larger data sets.
“Non-deep” machine learning is more dependent on human intervention for the learning process to happen because human experts must first determine the set of features so that the algorithm can understand the differences between data inputs, and this usually requires more structured data for the learning process.
“Deep” machine learning can leverage labelled datasets, also known as supervised learning, to inform its algorithm. However, it does not necessarily require a labelled dataset. It can ingest unstructured data in its raw form (e.g., text and images), and it can automatically determine the set of features that distinguishes between different categories of data. Figure 2 illustrates the difference between machine learning and deep learning.
Figure 2. The difference between machine learning and deep learning.
Deep learning uses multiple layers to progressively extract higher-level features from the raw input. For example, in image processing, lower layers may identify edges, while higher layers may identify the concepts relevant to a human, such as digits or letters or faces.
In deep learning, each level learns to transform its input data into a slightly more abstract and composite representation. In an image-recognition application, the raw input may be a matrix of pixels. The first representational layer may abstract the pixels and encode edges; the second layer may compose and encode arrangements of edges; the third layer may encode a nose and eyes; and the fourth layer may recognise that the image contains a face. Importantly, a deep learning process can learn which features to optimally place in which level on its own. This does not fully eliminate the need for manual-tuning – for example, varying numbers of layers and layer sizes can provide different degrees of abstraction. The word “deep” in “deep learning” refers to the number of layers through which the data is transformed.
NEURAL NETWORKS
An artificial neural network (ANN) is a computer system designed to work by classifying information in the same way a human brain does, while still retaining the innate advantages they hold over us, such as speed, accuracy and lack of bias. For example, it can be taught to recognise images and classify these according to elements they contain. Essentially, it works on a system of probability – based on data fed to it, it can make statements, decisions or predictions with a degree of certainty. The addition of a feedback loop enables “learning” – by sensing or being told whether its decisions are right or wrong, it modifies the approach it takes in the future.
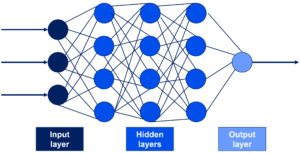
Artificial neural networks consist of a multilevel learning of detail or representations of data. Through these different layers, information passes from low-level parameters to higher-level parameters. These different levels correspond to various levels of data abstraction, leading to learning and recognition. An ANN is based on a collection of connected units called artificial neurons (analogous to biological neurons in a biological brain). Each connection (synapse) between neurons can transmit a signal from one neuron to another neuron. The receiving (postsynaptic) neuron can process the signal(s) and then signal to neurons connected to it downstream. Neurons may have state, generally represented by real numbers, typically between 0 and 1. Neurons and synapses may also have a weight that varies as learning proceeds, which can increase or decrease the strength of the signal that it sends downstream. Typically, neurons are organised in layers, as illustrated in Figure 3. Different layers can perform various kinds of transformations on their inputs. Signals travel from the first (input), to the last (output) layer, possibly after traversing the layers multiple times.
Figure 3. Layers in an artificial neural network.
USES OF MACHINE LEARNING
There are many applications for machine learning; it is one of the three key elements of Intelligent Automation and a autonomous operating model within Industry 4.0. The computer programs can read text and work out whether the writer was making a complaint or offering congratulations. They can listen to a piece of music, decide whether it is likely to make someone happy or sad, and find other pieces of music to match the mood. In some cases, they can even compose their own music that either expresses the same themes or is likely to be appreciated by the admirers of the original piece.
Neural networks have been used on a variety of tasks, including computer vision, speech recognition, machine translation, social network filtering, playing board and video games, and medical diagnosis. As of 2017, neural networks typically have a few thousand to a few million units and millions of connections. Although this number is several orders of magnitude less than the number of neurons in a human brain, these networks can perform many tasks at a level beyond that of humans (e.g., recognising faces, playing “Go”).
THE GOAL OF USING INTELLIGENT AUTOMATION
The goal of using Intelligent Automation (IA) is to achieve better business outcomes through streamlining and scaling decision making across businesses. IA adds value to business by increasing process speed, reducing costs, improving compliance and quality, increasing process resilience and optimising decision results. Ultimately, it improves customer and employee satisfaction and improves cash flow and EBITDA and decreases working capital.
WHAT IS INTELLIGENT AUTOMATION?
IA is a concept leveraging a new generation of software based automation. It combines methods and technologies to execute business processes automatically on behalf of knowledge workers. This automation is achieved by mimicking the capabilities of knowledge that workers use in performing their work activities (e.g., language, vision, execution and thinking & learning).IA effectively creates a software-based digital workforce that enables synergies by working hand-in-hand with the human workforce.
On the simpler end of the spectrum, IA helps perform the repetitive, low-value add and tedious work activities such as reconciling data or digitising and processing paper invoices. On the other end, IA augments workers by providing them with superhuman capabilities. For example, it provides the ability to analyse millions of data points from various sources in a few minutes and generate insights from.
THREE KEY COMPONENTS OF INTELLIGENT AUTOMATION
IA consists of three key components:
Business Process Management with Process Mining to provide greater agility and consistency to business processes.
Robotic Process Automation (RPA). Robotic process automation uses software robots, or bots, to complete repetitive manual tasks. RPA is both the gateway to artificial intelligence and can leverage insights from Artificial Intelligence to handle more complex tasks and use cases.
Artificial Intelligence. By using machine learning and complex algorithms to analyse structured and unstructured data, businesses can develop a knowledge base and formulate predictions based on that data. This is the decision engine of IA.
WHERE AND HOW TO START WITH INTELLIGENT AUTOMATION?
Implementing Intelligent Automation might come across as a daunting endeavour, but it doesn’t need be. Like any business leader, you will have a keen eye on accelerating operations performance, which in essence is improving the behaviour and outcomes of your business processes. Process Mining is a perfect tool to help you with that.
Process Mining is a data-driven analysis technique, i.e., analysis software, to objectively analyse and monitor business processes. It does this based on transactional data that is recorded in a company’s business information systems. The analysis software is system agnostic and doesn’t need any adaptation of your systems. Process Mining provides fact-based insight into how processes run in daily reality: all process variants (you will be surprised how many variations of one process there actually are in your business) and where the key problems and opportunities lie to improve process efficiency and effectiveness.
Process Mining is also an excellent way to prepare the introduction of Robotic Process Automation, which could be the most relevant next step on your IA journey. Process Mining can be purely used as an analysis tool, but it can also be installed permanently to constantly monitor the performance of and the issues in the processes. It is a non-intimidating approach and a gradual implementation of Intelligent Automation.
THE IMPORTANCE OF A COMPANY-WIDE VISION AND SHARED ROADMAP
However, at some point, rather sooner than later, it is important to establish and communicate a comprehensive, company-wide vision for what you want Intelligent Automation to achieve: how will automation deliver value and boost competitive advantage. You need a shared roadmap for a successful implementation that covers processes, technology (including legacy systems), people & competencies and organisation.
Such a shared Intelligent Automation/Industry 4.0 Roadmap ensures a consistent, thoughtful approach to selecting, developing, applying, and evolving the IA/I4.0 structure to achieve the intended impact. The Axisto Industry 4.0 Maturity Assessment (AIMA) is an effective way to create such a shared implementation roadmap.
THE CRUX TO SUCCESS LIES IN A WIDE-RANGE OF PEOPLE-ORIENTED FACTORS
Importantly, the biggest challenge for a company is not in choosing the right technology, but in having a lack of digital culture and skills in the organisation. Investing in the right technologies is important – but the success or failure does not ultimately depend on specific sensors, algorithms or analysis programs. The implementation and scaling of Intelligent Automation/Industry 4.0 requires a fundamental shift in mindset and behaviours at all levels in the organisation. The crux to success lies in a wide range of people-oriented factors.
Although companies have automated many of their processes, much of the work is still done manually and routinely. For example, employees have to manually enter data and switch between systems, applications and screens in order for the critical business processes to function. Such activities have no added value in themselves. They take time, pose an inherent risk and are expensive.
Axisto replaces these tasks with Robotic Process Automation (RPA), which performs the tasks 24/7, quickly and error-free. In this way, employees can contribute added value by focusing their attention and expertise on those tasks that are important. Freeing up time simplifies the transition from reactive to proactive operational processes. RPA is highly flexible – it can be used in many different areas and can be scaled up and down quickly. RPA adds value by better exploiting and expanding the possibilities of machine learning and artificial intelligence. Axisto provides advice to find your best options and supports you to implement these new ways of working.
Dealing with the uncertainty of “the new normal”
Many people talk about “the new normal”, but nobody really knows what it will look like. The increased volatility and financial risk will remain with us for a while; however, Robotic Process Automation (RPA) could well be a solution to help address this current uncertainty. RPA drives down costs, is adaptable to changing circumstances, reduces cycle time and increases quality. And, at the same time, RPA could be a suitable way to kick start your digital transformation journey.
Robotic Process Automation (RPA)
RPA uses digital robots (or bots) to automate mundane and repetitive tasks and processes in the workplace. A bot is a piece of software, programmed to do specific tasks on a computer. It is taught a workflow – and it can do more or less anything as long as the workflow can be defined. The bots mimic human behaviour and work well in a rule-based environment, preferably with structured data.
RPA and the operating model
In Part 5 we discussed the PMS operating model, which is supported by IT systems through the automated execution of business processes and which provides reporting functionality. In every performance improvement programme we conduct, we find that the operating model is not well-aligned with the vision and that people don’t have the information they need to do a good job. We know that the minimum requirement is decent reporting. To get this, people end up collecting bits and pieces of information from the various non-integrated IT legacy systems. Integration is costly and time consuming, so it is never done.
As a consequence, business effectiveness breaks down: employees carry out highly repetitive, boring, and transactional activities; companies handle high-volume, unstructured data in silos; data is underutilised for reporting, analysis and continuous improvement; and customers often face a fractured experience in contacting businesses. In short, high operating costs and low performance.
RPA addresses these issues fast, reliably and at a low cost. And on top of that, the programming of the bots can be easily adapted if circumstances and functionally requirements change. The bots are flexible, scaling up and down with demand.
RPA – a gateway to artificial intelligence (AI)
As RPA is IT-system agnostic it can interact with any technology platform. The bots can collect and process data from various cognitive technologies such as machine learning and computer vision – indeed, Optical Character Recognition (OCR) is a broadly applied technology.
We don’t see RPA having a long-term future on its own, but we do see it as a crucial piece in the puzzle of a true digital operating model that includes artificial intelligence. Dealing with the consequences of the coronavirus pandemic is, as we see it, a great time to kick start your digital transformation journey.
In November 2020, McKinsey published an interesting paper entitled “Value creation in industrials”, a survey of the US industrials sector. The purpose of the analysis was to gain insight into the factors that determine performance in the industrials sector. Value creation was used as an indicator, measured as annual growth of the total shareholder return (TSR). The research covers the period 2014–2019. So, what are the conclusions on how to create value in Industrials?
CONCLUSIONS
The industrials sector is broad and diverse. In order to compare companies in a meaningful way, McKinsey divided the sector into 90 so-called microverticals. More on that later.
The main conclusions about how to create value in Industrials:
Even in good times, TSR performance across and within microverticals is highly variable.
Despite the tailwind or headwind, companies ultimately determine their own destiny.
The TSR performance gap between the best-performing and worst-performing companies within a microvertical is substantial and growing.
Companies with strong balance sheets for 2019 have, on average, outperformed their competitors: the COVID-19 pandemic has widened the gap between the best and worst performers.
Operational performance, and in particular margin improvement, is by far the most important factor in value creation.
HOW CAN WE COMPARE COMPANIES IN SUCH A DIVERSE INDUSTRIAL SECTOR?
While the manufacturing sector performed well at an annual growth rate of 11 per cent between 2014 and 2019, performance varied widely between the ten subsectors. Now the diversity between and within the subsectors is very great. In order to properly identify the factors that determine the performance, the study worked with 90 groups of companies that carry similar products and that focus on a similar end market: the so-called microverticals.
WHICH TRENDS ARE AFFECTING THE MICROVERTICALS?
Five categories emerge from the research: (1) regulation, (2) consumer and socio-economic, (3) technological, (4) environment, and (5) industrial structure and movements of players in the market. Any one of these trends can cause a tailwind or headwind – often both. Measured in revenue and margin growth, these trends predominantly work out well for the top-performing microverticals and negatively for some of the bottom microverticals.
COMPARING MICROVERTICALS AND COMPANIES WITHIN THEM.
First of all, the fact that the company is in a top-performing microvertical is no guarantee that it is a top performer. It can also be seen that the best-performing companies within a microvertical perform substantially better than the worst-performing companies within the same microvertical. The performance gap is substantial and growing.
McKinsey found a 2,600 base point difference in TSR between the best- and worst-performing microverticals. Approximately 30 per cent of companies performed significantly better or worse than what the performance of their microverticals would have predicted. So success depends not only on whether you are in the “right” microvertical; a company’s actions are also important. Individual companies can do a lot to determine their fate, even when headwinds and tailwinds affect microvertical performance. Furthermore, the survey found that, on average, companies with strong balance sheets for 2019 outperformed their competitors, meaning the COVID-19 pandemic has widened the gap between the best and worst performers.
WHAT CAN WE LEARN FROM THE BEST COMPANIES?
To determine which actions matter at a company level, the TSR performance of individual companies was analysed. To this end, the TSR was divided into three broad elements:
1. Operational performance
This element refers to how a company uses its capital to increase revenues and operating margins; this category also includes a company’s ability to generate value for its shareholders in a scenario with no growth and unchanged profitability. The latter is a measure of the starting position of a company.
2. Leverage
Leverage refers to how companies use debt to improve their TSR performance.
3. Multiple expansion
This element refers to opportunities to take advantage of changes in how investors see the future.
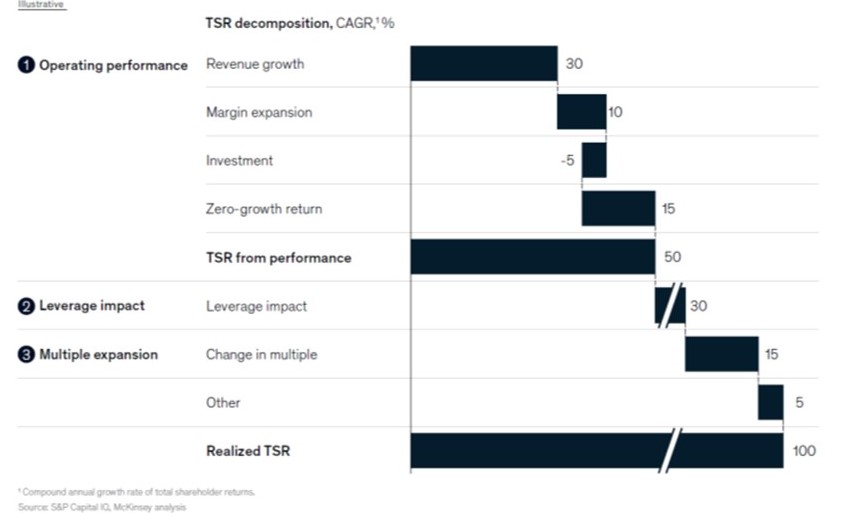
Figure 1 provides insight into the way in which companies secured their position.
Figure 1. The way in which companies secured their position.
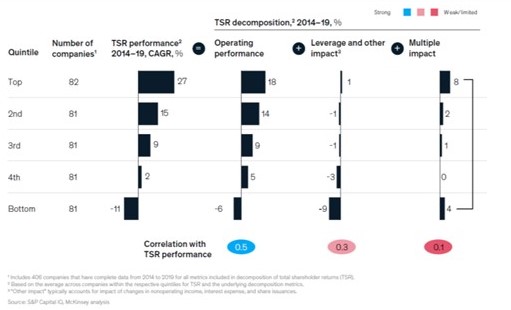
Of the three elements of TSR, operational performance was found to be the strongest predictor of TSR CAGR from 2014 to 2019 for all quintiles (Figure 2). Operational performance had the highest correlation coefficient with TSR performance, at 50 per cent, followed by leverage (about 30 per cent) and multiple expansion (about 10 per cent).
At the top-performing companies, operating performance contributed to 18 percentage points of the 27 per cent TSR growth. And for the worst performing companies −6 percentage points of −11 per cent TSR growth.
Figure 2. Operating performance had the strongest correlation with the company TSR.
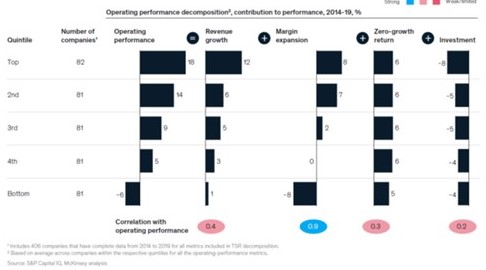
Within the operational measures, margin expansion was a major contributing factor and also the strongest determinant of the company’s TSR performance (Figure 3). With a 90 per cent correlation to business performance, the profitability extension (margin) adds an average of 8 percentage points to the 18 per cent operational performance of the top performing companies and takes 8 percentage points away from the lowest quintile companies, where the business performance is on average −6 percent.
Figure 3. From the operational statistics, margin expansion proved (often made possible by technology) the main determining factor for the company’s TSR.
Looking at the top-performing companies, it turned out that their success had depended mainly on taking three steps:
HOW DO YOU ENABLE SUCCESS AND HOW DO YOU MAINTAIN IT?
To further increase the likelihood of continued success, companies need good supervision. Executives must balance their time between creating and executing strategies, and periodically reassessing and rebalancing the business portfolio. Along the way, they should look for ways to improve earning power through rapid (two-year) cycles of margin transformation, leveraging technology wherever possible.
Industry 4.0 is in the spotlight. And rightly so. The possibilities are great: higher productivity, a better customer experience, lower costs and perhaps a new business strategy with innovative products and services. And there is an outright need: without Industry 4.0 a company has a limited future. Unfortunately, many Industry 4.0 implementations get stuck. Let’s find out why this happens and how to prevent it happening to you.
DATA
There can be three issues with data: not good, not available, poor quality. This is often due to IT systems not being set up properly, data not being entered or being entered incorrectly, log switches to register log data not being set correctly, or the data entered being of poor quality.
In addition, the knowledge of business processes is seldom up to standard. How do processes behave in daily practice? How should they run? This means that people are unclear as to which data should be captured and how the data should be managed.
It is therefore important to know the business processes and how they work both in theory and in practice. This is the basis for a good KPI and reporting structure. Getting this right will ensure clarity around which data must be collected, which information is required for whom at what time and how to manage the processes for maximum effect. It will also mean that data availability and quality will increase – thus building the foundation for Industry 4.0.
ORGANISATIONAL SILOS
Many companies still have a strong departmental orientation instead of an end-to-end process focus. This leads to limited insight into and understanding of the interdependencies between functions and departments. A strong departmental orientation also means that data is locked up in silos.
Industry 4.0 focuses on the integrated control of the end-to-end processes that run through various departments and even across company boundaries. That is why departments are asked to work together seamlessly and to share data and information. An effective IT infrastructure facilitates this.
CAPABILITIES TO COLLECT AND USE DATA
The introduction of Industry 4.0 requires a significantly higher level of knowledge of the
industry, of business processes and of analysis applications. At every level in the company and within every position, people must be able to handle data well and be skilled in its analysis.
The technical structure of these cyber-physical systems is becoming more complex, and more and more decisions are being made by algorithms. Therefore, it is important that companies develop the knowledge and skills to build applications and assess the behaviour of algorithms and the insights they provide. The introduction of Industry 4.0 requires intensive collaboration between departments and disciplines to develop people and resources at pace.
VISION AND ORGANISATIONAL ALIGNMENT
The introduction of Industry 4.0 affects all aspects of an operating model. The top team needs a shared vision about the value that is required for various stakeholders, and how that value is delivered – the operating model.
Too often, a joint vision is ill-considered and not adequately thought through, resulting in insufficient alignment with the roadmap. In such a situation, an implementation inevitably comes to a standstill.
THE HUMAN FACTOR
The biggest challenge in an Industry 4.0 implementation is not so much choosing the right technology, but dealing with the absence of a data-based and digital performance culture and the corresponding skills gap in the organisation. Investing in the right technologies is important – but success or failure ultimately does not depend on specific sensors, algorithms or analysis programs. The crux lies in a wide range of people-oriented factors.
Since Industry 4.0 transcends not only internal departments but also the boundaries of the company, its success is predominantly dependent on skillful change management.
CONCLUSION
In essence, the reasons why Industry 4.0 implementations get stuck are no different than with other company-wide transformations whose aim is to create a sustainably high-performing organisation. It will not surprise you that the chance of failure is roughly the same: 70%.
Therefore, in the first instance, do not focus too much on just the technical side of the transformation. Instead, concentrate on skilful change management. The technological content side of the transformation is not your main problem. The development of a data-based and digital performance culture and the corresponding skills set is.
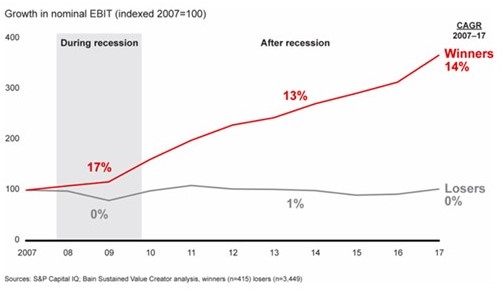
Inevitably, after every recession the economy grows again. Research by Bain & Company, Harvard Business Review, Deloitte, and McKinsey shows that the best companies continue to grow their EBIT during a recession and also accelerate faster after it when compared to other companies (see Figure 1). Let’s take a look at what the winners do differently to accelerate their profitability during and after a recession.
Figure 1. “Winning companies accelerated profitability during and after the recession, while losers stalled” (Source: Bain & Company).
7 KEY ACTIONS TO ACCELERATE YOUR PROFITABILITY DURING AND AFTER A RECESSION
We’ve integrated this research material to generate a clear picture of the 7 key actions you need to take for success.
1. CREATE CLARITY OF DIRECTION AND ORGANISATIONAL ALIGNMENT
How do you want your company to look and run in three to five years from now? And in one year? What are the vital few strategic initiatives to focus on? Make sure your leadership team is committed and fully aligned.
2. UNDERSTAND YOUR STRATEGIC AND FINANCIAL POSITION
Mapping out your plans depends on your strategic and financial position
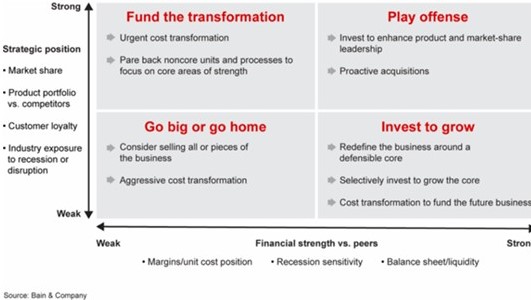
(see Figure 2).
Figure 2. Mapping out your plans requires an assessment of your company’s strategic and financial position (Source: Bain & Company).
3. FREE UP “CURRENCY”
This is not about blunt cost cutting; the focus is on aligning your spending with your vision and strategic initiatives. Zero-based Alignment / Budgeting is a good way to select and make lean those activities that are fully aligned. The “currency” you free up can strengthen your balance sheet and support your investment agenda.
4. RETAIN YOUR CUSTOMERS
Retaining your customers is so much cheaper than acquiring new ones. The margin impact is significant. Explore ways to help your customers through the downturn and strengthen your relation with them. And be sure to focus on the right customers.
5. PLAN FOR VARIOUS SCENARIOS
Nobody knows when and how a downturn will unfold and when the economy will start to grow again. The winners have developed various scenarios, and they know how they should act in each scenario. This allows them to move quickly and decisively.
6. ACT QUICKLY AND DECISIVELY
Winning companies act quickly and decisively, both in the downturn and particularly in the early upturn when the opportunities start to arise. They have already created the “currency” to invest.
Not all companies have been equally aggressive in adopting new technologies. There are many opportunities here for improving efficiency or generating more value and thereby gaining a competitive advantage. The current COVID19 pandemic could well be an important catalyst.
This means that you have to be prepared for an economic downturn to come out as one of the winners. It should be noted that in these key actions, there is, in fact, no difference between being prepared for an economic downturn and running a business for continuous and maximum success. This picture is consistent with one that emerges from one of our other articles “How to create value in Industrials?”.


 Business Process Management with Process Mining to provide greater agility and consistency to business processes.
Business Process Management with Process Mining to provide greater agility and consistency to business processes. Robotic Process Automation (RPA). Robotic process automation uses software robots, or bots, to complete repetitive manual tasks. RPA is both the gateway to artificial intelligence and can leverage insights from Artificial Intelligence to handle more complex tasks and use cases.
Robotic Process Automation (RPA). Robotic process automation uses software robots, or bots, to complete repetitive manual tasks. RPA is both the gateway to artificial intelligence and can leverage insights from Artificial Intelligence to handle more complex tasks and use cases. Artificial Intelligence. By using
Artificial Intelligence. By using  Importantly, the biggest challenge for a company is not in choosing the right technology, but in having a lack of digital culture and skills in the organisation. Investing in the right technologies is important – but the success or failure does not ultimately depend on specific sensors, algorithms or analysis programs. The implementation and scaling of Intelligent Automation/Industry 4.0 requires a fundamental shift in mindset and behaviours at all levels in the organisation.
Importantly, the biggest challenge for a company is not in choosing the right technology, but in having a lack of digital culture and skills in the organisation. Investing in the right technologies is important – but the success or failure does not ultimately depend on specific sensors, algorithms or analysis programs. The implementation and scaling of Intelligent Automation/Industry 4.0 requires a fundamental shift in mindset and behaviours at all levels in the organisation.