Bedrijven in de EU moeten zich voorbereiden op ESG-rapportage onder de Corporate Sustainability Reporting Directive (CSRD), die in 2024 van start is gegaan.
De deadlines voor naleving variëren:
Grote bedrijven van openbaar belang moeten rapporteren vanaf 1 januari 2024. Andere grote bedrijven starten op 1 januari 2025. Beursgenoteerde mkb-bedrijven moeten rapporteren vanaf 1 januari 2026, met een opt-out mogelijkheid tot 2028.
De CSRD vereist gedetailleerde ESG-rapportage, afgestemd op de Europese Sustainability Reporting Standards (ESRS), en audits. Bedrijven moeten interne processen opzetten om duurzaamheidsgegevens te verzamelen en te verifiëren, en zorgen voor samenwerking tussen afdelingen. Echter, ESG-rapportage is vaak een complex en tijdrovend proces, wat het tot een uitstekende kandidaat maakt voor automatisering. Hi Automation biedt met UiPath RPA (Robotic Process Automation) en RaccoonDoc IDP (Intelligent Document Processing) een effectieve oplossing om ESG-rapportages te stroomlijnen en te verbeteren. Door ESG-rapportage te automatiseren, kunnen bedrijven tot wel 70% van de tijd die normaal besteed wordt aan gegevensverzameling en -verwerking besparen, waardoor teams zich kunnen richten op meer strategische en waardevolle activiteiten.
HOE EEN NEDERLANDS BEDRIJF DEZE UITDAGING IS AANGEGAAN
Laten we het verhaal bekijken van een van onze klanten, een groot productiebedrijf gevestigd in Nederland, en hoe zij hun ESG-rapportageproces hebben getransformeerd met behulp van de RPA- en IDP-oplossingen van Hi Automation.
De uitdaging: Een lappendeken aan gegevensbronnen voor het ESG-rapport
Onze klant, een gerenommeerd productiebedrijf, worstelde met de groeiende eisen van ESG-rapportage. De benodigde gegevens voor deze rapporten waren verspreid over verschillende afdelingen, van financiën tot inkoop en supply chain. Het consolideren van al deze informatie was tijdrovend en foutgevoelig, waarbij handmatige gegevensinvoer een foutenmarge van 10% had. De steeds veranderende regelgeving, zoals naleving van de EU Taxonomie en de Corporate Sustainability Reporting Directive (CSRD), voegde extra complexiteit toe aan hun processen.
Het ESG-team van het bedrijf besteedde jaarlijks meer dan 500 uur aan het verzamelen van gegevens en rapporteren—tijd die beter besteed had kunnen worden aan strategische duurzaamheidsinitiatieven. Daarnaast stond het team onder grote druk om de nauwkeurigheid van de gegevens te waarborgen en aan strikte deadlines te voldoen. Het werd duidelijk dat een nieuwe aanpak nodig was, een aanpak die het ESG-rapportageproces zou automatiseren en vereenvoudigen.
De oplossing: Automatisering met RPA en IDP
Zich realiserend dat dit alleen met automatisering te doen is, wendde het bedrijf zich tot Hi Automation. We begonnen met een grondige evaluatie van hun ESG-rapportageprocessen om de belangrijkste knelpunten te identificeren. Ons team stelde een op maat gemaakte oplossing voor, gebruikmakend van de UiPath RPA-mogelijkheden in combinatie met RaccoonDoc Intelligent Document Processing.
De implementatie begon met het automatiseren van het gegevensverzamelingsproces. Met behulp van RPA hebben we bots gecreëerd die gegevens uit meerdere systemen en afdelingen konden verzamelen om deze vervolgens automatisch consolideerden in een datacentrum. Dit verkortte de tijd die besteed werd aan gegevensverzameling met 80%. Met behulp van IDP hebben we ongestructureerde gegevensbronnen, zoals facturen en documenten uit de supply chain, aangepakt, waarbij de benodigde informatie met meer dan 90% nauwkeurigheid werd geëxtraheerd. De automatisering omvatte ook ingebouwde validatiecontroles om gegevensconsistentie en betrouwbaarheid te waarborgen.
Het resultaat: Efficiëntie, nauwkeurigheid en compliance
De transformatie was indrukwekkend. De tijd die nodig was voor ESG-rapportage werd met 65% verminderd, waardoor het ESG-team zich kon concentreren op strategische projecten in plaats van op routinematige datataken. De geautomatiseerde gegevensverzameling en -verwerking verbeterde de nauwkeurigheid van hun rapporten tot 98%, waardoor het risico op nalevingsproblemen aanzienlijk werd verminderd. Met audit-klare rapporten binnen handbereik voelde het bedrijf zich zeker dat ze aan de regelgeving konden voldoen zonder last-minute stress.
Naast tijdsbesparing was de financiële impact aanzienlijk. Het bedrijf meldde een kostenreductie van 40% op het gebied van ESG-gegevensbeheer. De transparantie en real-time monitoring van de automatisering versterkten ook het vertrouwen van belanghebbenden, wat de reputatie van het bedrijf bij investeerders en partners verbeterde. Door ESG-rapportage te automatiseren, voldeed het bedrijf niet alleen aan de wettelijke vereisten, maar positioneerde het zich ook als een koploper op het gebied van duurzaamheid binnen hun sector.
WAAROM DE AANPAK VAN HI AUTOMATION UNIEK IS
Dit project illustreert waarom de aanpak van Hi Automation voor ESG-rapportage de beste keuze is voor bedrijven die hun processen willen stroomlijnen en hun duurzaamheidsinspanningen willen verbeteren.
Schaalbaarheid en flexibiliteit:
De RPA- en IDP-oplossing is ontworpen om flexibel en schaalbaar te zijn, zodat het bedrijf zich snel kan aanpassen aan veranderingen in ESG-regelgeving. Deze flexibiliteit zorgt ervoor dat ze kunnen voldoen aan nieuwe eisen zonder hun processen opnieuw te moeten ontwerpen.
Aanpasbare workflows:
We hebben de geautomatiseerde workflows aangepast aan de specifieke behoeften van het bedrijf. Dit betekende een naadloze integratie met hun bestaande systemen en de zekerheid dat de oplossing was toegespitst op hun unieke complexiteit.
Gebruiksvriendelijke implementatie:
Een belangrijk voordeel van onze aanpak is de toegankelijkheid. Medewerkers zonder technische expertise konden zich binnen twee weken aanpassen aan de nieuwe tools, wat zorgde voor een snelle return on investment.
HET BREDERE PERSPECTIEF: VOORDELEN VAN ESG-AUTOMATISERING
De voordelen van het automatiseren van de ESG-rapportage gaan veel verder dan alleen tijd- en kostenbesparing. Voor onze klant betekende dit:
Verbeterde gegevenskwaliteit:
De automatisering elimineerde vrijwel alle menselijke fouten, waardoor ESG-rapporten betrouwbaar waren en voldeden aan de verwachtingen van belanghebbenden. Dit leidde tot een verbetering van 98% in de nauwkeurigheid van de gegevens.
Lagere kosten en minder tijd:
Door handmatig werk te minimaliseren, zag het bedrijf een kostenreductie van 50% en een tijdsbesparing van 60% in de rapportage. Deze efficiëntie maakte middelen vrij die konden worden herinvesteerd in andere strategische initiatieven.
Verbeterde naleving en transparantie:
Automatisering zorgde voor real-time monitoring en directe rapportage, waardoor het bedrijf compliant bleef met zowel lokale als internationale ESG-regelgeving. De transparantie bevorderde ook meer vertrouwen bij belanghebbenden, waaronder toezichthouders en investeerders.
Duurzame groei:
De tijds- en kostenbesparingen die door automatisering werden gegenereerd, investeert het bedrijf nu in verduurzamen en groeien. Hun verbeterde ESG-prestaties hebben een positief effect op investeerders aan en versterkten hun merkreputatie als leider in duurzaamheid.
BEGINNEN MET ESG-AUTOMATISERING
Het succes van dit project toont aan dat het automatiseren van ESG-rapportage niet alleen mogelijk is, maar een strategische noodzaak is voor bedrijven die voorop willen blijven lopen in een competitieve en steeds strengere gereguleerde omgeving. Bedrijven die deze reis willen beginnen, kunnen de volgende stappen volgen:
Beoordeling:
Identificeer de belangrijkste ESG-rapportageprocessen die kunnen profiteren van automatisering, met de focus op gebieden waar handmatig werk het meest tijdrovend is. Ons team bij Hi Automation kan een gratis beoordeling uitvoeren om deze kansen te identificeren.
Implementatie:
Voer een gefaseerde aanpak uit voor de implementatie van RPA en IDP, met minimale verstoring van de huidige operaties en een maximale impact van de automatisering.
We garanderen een soepele implementatie, waarbij meer dan 90% van onze projecten binnen de geplande tijdlijn wordt voltooid.
Continue verbetering:
Maak gebruik van automatisering om de ESG-gegevensverzameling en rapportage voortdurend te verbeteren. Onze oplossing bevat AI-gebaseerde analyses om de ESG-prestaties te monitoren en optimaliseren, zodat u voorop blijft lopen bij veranderingen in regelgeving en industrienormen.
CONCLUSIE
Het automatiseren van ESG-rapportage met UiPath RPA en RaccoonDoc IDP biedt aanzienlijke waarde voor Nederlandse bedrijven, waardoor ze groei goed kunnen combineren met verduurzamen. De expertise van Hi Automation zorgt ervoor dat ESG-rapportageprocessen efficiënt, nauwkeurig en conform de regelgeving zijn, waardoor bedrijven zich kunnen richten op hun kernactiviteiten en tegelijkertijd hoge duurzaamheidsnormen kunnen handhaven. Met tijds- en kostenbesparingen tot wel 70% is automatisering de beste manier om ESG-uitdagingen effectief aan te pakken. Neem vandaag nog contact op met Hi Automation om te ontdekken hoe automatisering kan worden afgestemd op uw unieke ESG-uitdagingen.
Wat is Intelligent Document Processing?
Intelligente Documentverwerking (IDP) revolutioneert de manier waarop bedrijven documenten behandelen en interpreteren, waarbij geavanceerde AI- en Machine Learning-technologieën worden ingezet. Het automatiseert de extractie, begrip en verwerking van gegevens uit verschillende documentformaten, waardoor ongestructureerde inhoud wordt omgezet in bruikbare inzichten. IDP verbetert efficiëntie, nauwkeurigheid en besluitvorming, waardoor organisaties zich kunnen richten op strategische groei en klanttevredenheid..
Wat zijn de voordelen van IDP?
Intelligente Document Verwerking (IDP) biedt enorme voordelen door de extractie en interpretatie van gegevens over diverse documenttypen te automatiseren. Belangrijke voordelen zijn aanzienlijke tijdsbesparingen door verminderde handmatige gegevensinvoer, verbeterde nauwkeurigheid met minimale foutenpercentages en verbeterde compliance. Bovendien ontgrendelt IDP waardevolle inzichten uit ongestructureerde gegevens, waardoor gewonnen wordt aan betere besluitvorming en operationele efficiëntie. Dit leidt tot gestroomlijnde werkprocessen, kostenbesparingen en verhoogde klantbeleving, waardoor bedrijven aan concurrentiekracht winnen en meer groei realiseren.
Meer Efficiëntie
IDP kan grote hoeveelheden documenten nauwkeurig en snel verwerken, wat leidt tot meer efficiëntie en kortere verwerkingstijden. Dit elimineert de noodzaak voor handmatige gegevensinvoer en andere repetitieve taken, waardoor medewerkers zich kunnen concentreren op kerntaken die menselijk oordeel en besluitvorming vereisen.
Betere Nauwkeurigheid
IDP gebruikt technologieën zoals OCR en AI om gegevens nauwkeurig uit documenten te extraheren. Ze verminderen het risico op fouten en zorgen ervoor dat de geëxtraheerde gegevens betrouwbaar zijn en voldoen aan relevante voorschriften en normen. Door de extractie en validatie van gegevens te automatiseren, verbetert IDP de nauwkeurigheid van document verwerking, wat leidt tot betere bedrijfsresultaten.
Minder Kosten
Door de verwerking van documenten te automatiseren, vermindert IDP de noodzaak voor handmatige interventie, wat leidt tot minder kosten. IDP vermindert de noodzaak voor menselijke betrokkenheid.
Betere Service
IDP kan bedrijven helpen hun klantenservice te verbeteren door kortere verwerkingstijden en betere nauwkeurigheid. Dit leidt tot snellere verwerking van klantaanvragen, betere gegevenskwaliteit en verbeterde klanttevredenheid.
Schaalbaar
IDP is schaalbaar en kan grote hoeveelheden gegevens verwerken. Dit maakt IDP ideaal voor bedrijven van elke omvang, van kleine startup tot grote onderneming. Het kan ook worden aangepast aan verschillende bedrijfsprocessen om aan specifieke behoeften te voldoen, waardoor het een veelzijdige technologie is.
Betere Compliance
IDP helpt bedrijven te voldoen aan voorschriften en normen door geëxtraheerde gegevens die nauwkeurig en compliant zijn. Dit vermindert het risico op boetes en helpt bedrijven een goede reputatie op te bouwen bij klanten en regelgevende instanties.
Geautomatiseerde Documentverwerking voor uw Industrie
Intelligent Document Processing – enkele voorbeelden van toepassingen
Realiseer een doorbraak in uw documentverwerking
IDP in uw branche is niet alleen een technologische upgrade, het is een strategische zet op het gebied van efficiëntie, nauwkeurigheid en concurrentievermogen. Hi Automation helpt u bij het automatiseren van cruciale documenten om tijd en middelen besparen, zodat u zich kunt richten op groei. IDP is een kernelement in de digitale transformatie naar een toekomst, waarin gegevens efficiënt worden beheerd en meer waarde uit tekst wordt geëxtraheerd.
Het beeld van een vrij traditionele Nederlandse bouwsector draait nu snel naar een sector die steeds meer innoveert en digitaliseert. Onder de druk van veranderende regelgeving ten aanzien van stikstof en duurzaamheid, gestegen inkoopkosten die lastiger zijn door te berekenen en een tekort aan geschoolde arbeidskrachten ontwikkelt de sector zich snel.
Hi automation ondersteunt Aannemers en Contractors op verschillende manieren in het versneld verbeteren van hun operationele en financiële prestatie. In dit artikel richten wij ons op slechts een element daarvan: het efficiënt navigeren door en verwerken van informatie uit de vele documenten die samenhangen met de werkzaamheden in deze sector.
De sector kent een overvloed aan documenten
We hebben het over tenderdocumenten, contracten, tekeningen, facturen, diverse documenten met betrekking tot personeel, veiligheidsrapporten, compliance documenten. Het is een aantal van de vele documenten waar deze sector mee te maken heeft.
Snel, efficiënt en foutloos navigeren door de inhoud uit al deze documenten en vervolgens verwerken, is een grote uitdaging. Het maken van fouten ligt voortdurend op de loer, omdat dit vaak geheel of gedeeltelijk handmatig gebeurt. De consequenties van fouten kunnen significant zijn: vertragingen, boetes, verlies aan marge door faalkosten.
Hoewel er een verschuiving is naar digitaal documentbeheer, blijft de implementatie en het onderhoud ervan een administratieve uitdaging.
Intelligente Documentverwerking (IDP – Intelligent Document Processing) biedt de uitkomst.
Wat is Intelligente Documentverwerking (IDP)?
IDP is software die uw document opent, ongeacht het format (PdF, Word, hard copy, etc.), de inhoud leest, de cruciale informatie eruit haalt om die vervolgens eventueel te bewerken en dan te verwerken in de diverse systemen die u gebruikt.
Een document wordt geopend en vervolgens wordt de inhoud toegankelijk gemaakt door middel van OCR (Optical Character Recognition), de inhoud wordt gelezen door gebruik te maken van NLP (Natural Language Processing). ML (Machine Learning) wordt gebruikt om de tekst te begrijpen en de belangrijke informatie te herkennen. Tenslotte wordt die informatie geëxtraheerd en getransporteerd naar de volgende stap. Die kan zijn het verwerken in systemen, maar kan ook een serie van bewerkingen zijn om het resultaat vervolgens te verwerken in systemen.
Het maakt niet uit of de aangeboden documenten duidelijk en op een vaste manier zijn ingedeeld (gestructureerde data) of dat het vrije tekst (ongestructureerde data) is.
De voordelen zijn evident
Verbeterde kwaliteit: Verwerking van gegevens door mensen betekent onherroepelijk fouten. Al zijn het maar typefouten. IDP maakt deze niet.
Tempo: Het tot zich nemen van informatie, de belangrijke informatie extraheren en verder verwerken kost tijd. IDP is vele malen sneller dan uw medewerkers met alle voordelen van dien voor de uitvoering van de werkzaamheden die wel waarde toevoegen.
Betere compliance: Compliance betekent precies volgens de regels werken zonder fouten of vrije interpretatie. IDP werkt te allen tijde volgens de regels en maakt geen fouten met als gevolg een hoge compliance of signalering van non-compliance.
Betere data analyse: Doordat de gegevens snel, consistent en foutloos worden verwerkt is de basis voor data analyse van hoge kwaliteit en zo ook de inzichten die de analyse verschaft en daarmee de kwaliteit van uw besluitvorming.
Zeker niet te vergeten is dat er minder druk op uw medewerkers staat, zij productiever kunnen zijn; met meer plezier in het werk. Immers, het werk dat nou eenmaal gedaan moet worden voordat ze met hun eigenlijk werk kunnen beginnen is overgenomen door IDP.
Op maat gesneden oplossingen en naadloze integratie
DP is geen “one size fits all” oplossing. Het Intelligente Documentverwerkingssysteem wordt volledig voor uw specifieke situatie geconfigureerd: Het type documenten waar u mee te maken hebt en de workflows die u gebruikt.
IDP integreert naadloos met de software die u nu gebruikt, zoals uw ERP-systeem en project management tools. Het voedt uw systemen automatisch zonder dat deze moeten worden aangepast. De inzet van IDP stelt de belangrijke consistentie van data in de verschillende systemen en afdelingen zeker.
Wat een implementatie succesvol maakt
De nummer 1 bepalende factor zijn uw mensen. Het is belangrijk dat zij zich mede-eigenaar voelen van de verandering en dat zij erin vertrouwen dat zij zelf mee kunnen in die verandering. Vier elementen zijn dan van belang: (1) Dat ze begrijpen waarom de verandering wordt doorgevoerd. (2) Dat ze direct vanaf begin zijn betrokken en mee kunnen ontwikkelen. (3) Een goede training opdat uw team bedreven is in het gebruik van IDP-technologieën. En (4) invoering van een “community of practice” – een omgeving waarin gebruikers ervaringen en tips met elkaar delen en waar ze aan de hand van up-to-date trainingsmateriaal goed op de hoogte blijven van nieuwe functies en mogelijkheden. De tweede bepalende factor is doorlopende ondersteuning en onderhoud.. Regelmatige updates en onderhoudscontroles kunnen downtime voorkomen en ervoor zorgen dat het systeem efficiënt blijft werken. De derde factor is uiteraard gegevensbeveiliging. Gezien de gevoelige aard van de documenten is implementatie van solide beveiligingsmaatregelen in uw IDP-systeem van het grootste belang. Zorg ervoor dat het systeem voldoet aan de industrienormen voor gegevensbescherming, zodat uw gegevens beschermd zijn tegen onbevoegde toegang en inbreuken. Tenslotte is continue monitoring en evaluatie van de prestatie van het IDP-systeem van belang om de impact daarvan op de operatie te begrijpen. Daartoe kunt u indicatoren als verwerkingstijd, foutpercentages en gebruikerstevredenheid gebruiken om de effectiviteit te bepalen en verder te verbeteren. Regelmatige beoordelingen zullen u helpen het systeem in de loop van de tijd te optimaliseren en ervoor te zorgen dat het blijft voldoen aan de veranderende behoeften van uw bedrijf.
Wellicht weet u na al voldoende om met ons de inzet van IDP in uw bedrijf verder te verkennen. Wellicht wilt u nog wat meer inspiratie opdoen aan de hand van een aantal toepassingsvoorbeelden. In het onderstaande hebben we er een aantal op een rijtje gezet.
Hoe bedrijven IDP inzetten – enkele voorbeelden
1. Ontvangen, Controleren en Verwerken van Facturen
Aannemers, Contractors en opdrachtgevers werken over het algemeen met een (groot) aantal onderaannemers. Er ontstaat een continue stroom van werkorders, opdrachten, bestellingen en rekeningen. Uitdaging:
Deze stroom is al snel heel omvangrijk en verloopt vaak met horten en stoten – geen mooie continue flow. De inspanning om deze stroom snel en correct af te handelen, groeit de administratieve afdeling al snel boven het hoofd. Gevolg:
De consequenties variëren van vervelend (correctie van een reeds gedane betaling) tot en met zeer vervelende (boetes, rechtszaken, onderaannemers die niet meer voor de opdrachtgever willen werken, reputatieschade). Oplossing:
Intelligente Documentverwerking opent binnenkomende facturen, leest en controleert de inhoud op volledigheid en verzorgt de reconciliatie. Dit gaat razendsnel. Wanneer alles volledig en correct is, kan IDP de betalingsopdracht klaar zetten. Wanneer er zaken niet correct zijn, zal IDP deze voorleggen aan de Administratie voor aanvullende acties. Resultaat:
De Administratie werkt aan die zaken die hun expertise vragen, betalingen zijn niet te laat of te vroeg maar mooi op tijd, geen boetes of rechtszaken. De impact op kwaliteit van samenwerking en reputatie is evident.
2. Management of Change (MOC)
Daar waar werk wordt uitgevoerd, worden veranderingen doorgevoerd. Voorkomen van fouten is uiteraard beter dan genezen (effectief managen van de impact van de veranderingen). Dit loopt van een verandering van de scope in zijn meest omvangrijke vorm tot en met meer- minderwerk in de uitvoering. Uitdaging:
MOC is zeer complex en daarmee zeer gevoelig voor fouten, omdat een verandering op meerder plekken impact heeft: van tekening en “bill of material” tot en met de inhoud van een opdrachtomschrijving. Gevolg:
De consequenties variëren van substantiële vertragingen in de uitvoering, kostenoverschrijdingen, tekeningen en technische specificaties die niet meer overeenkomen met de “as built” situatie en afwijkingen tussen facturen en inkoopopdrachten. Oplossing:
Intelligent Document Processing (IDP) ondersteunt het snel en correct vastleggen en verwerken van wijzigen in de gehele lijn. Resultaat:
Geen misverstanden, miscommunicatie, onnodige kostenoverschrijdingen, onnodige vertragingen of foutieve verrekeningen meer ten gevolge van doorgevoerde veranderingen.
3. Automatisch Verwerken van Vrachtbrieven en Inkoopopdrachten
Dagelijks worden goederen afgeleverd op project- en opdrachtlocaties en daar komt het nodige papierwerk, zoals vrachtbrieven en inkoopopdrachten bij kijken. Uitdaging:
Het kan op momenten een flinke goederenstroom binnenkomen, maar ook een substantiële uitgaande stroom, zoals (gecontamineerd) afval en equipment dat gereinigd moet worden. De traditionele handmatige methoden van ontvangstregistratie, matchen met de bestelling en registreren en opvolgen van afwijkingen kunnen dan nog wel eens vastlopen. Gevolg:
Handmatige verwerking kan leiden tot vertragingen en foute registraties die op zichzelf weer kunnen leiden tot onnodig zoeken naar goederen die geregistreerd staan als geleverd maar dat feitelijk nooit zijn geweest en ook foutieve verrekeningen. Oplossing:
Intelligent Document Processing (IDP) automatiseert de gegevensextractie van vrachtbrieven en inkooporders. Daardoor worden alle details snel en correct vastgelegd en geïntegreerd in de workflow van het project of de opdracht. Resultaat:
Het is direct duidelijk of de bestelde goederen geleverd zijn, in welke hoeveelheden en wat de afwijkingen zijn. Vertragingen bij inkomende en uitgaande goederenstromen verdwijnen en de financiële afhandeling verloopt soepel; alles zonder allerlei correcties achteraf.
4. Automatic Processing of Invoices for Rental Equipment
Eigenlijk elke activiteit binnen de Aannemerij en Contractors gaat vraagt huurequipment: kranen, tijdelijke energievoorziening, slangen, specialistisch handgereedschap, steigers, verlichting en ga zo maar door. Vaak zijn er verschillende partijen die equipment huren, de opdrachtgever, de hoofdaannemer, de onderaannemers. Soms heeft de opdrachtgever speciale contracten onderhandeld met leveranciers van huurequipment die de (sub)contractors moeten gebruiken en vervolgens op de juiste manier moeten doorberekenen. Uitdaging:
Facturen kunnen via allerlei verschillende kanalen bij de opdrachtgever binnen komen: op papier, via de mail, verwerkt in andere facturen, etc. Gegeven de hoeveelheid aan facturen en variatie aan condities is de kans groot dat het in de administratieve fout gaat. Gevolg:
Due to the complexity, errors can easily occur: invoices are booked and paid incorrectly, special conditions are not honoured, discrepancies between rental periods and charges arise, and more. Oplossing:
Intelligent Document Processing (IDP) automatiseert ook de administratieve afhandeling van huurequipment; doet dat snel en foutloos. IDP verzorgt een zorgvuldige controle, zet betalingen klaar voor wat goed is en signaleert daar waar additionele controle noodzakelijk is. Resultaat:
De inzet van IDP verhoogt niet alleen de productiviteit van de Administratie, maar ook het werkplezier door minder druk en tijd voor die zaken die hun expertise vraagt. Facturen worden correct voldaan, niet te vroeg en niet te laat met een goede leverancierstevredenheid tot gevolg en een goede basis voor mogelijk een verdere verbetering van de huurcondities.
5. Snellere “onboarding” van leveranciers, partners en medewerkers
Aannemers en Contractors zijn sterk afhankelijk van netwerken en tijdelijke relaties. Snel integreren van nieuwe leveranciers, partners en medewerkers en vervolgens eventueel weer afscheid nemen van hen, is dus van groot belang. Uitdaging:
Er gaat erg veel werk zitten in de initiële integratie – onboarding – van partijen. Een handmatige aanpak kost veel tijd en is foutgevoelig. Hetzelfde geldt overigens ook voor het verbreken van de relatie – de offboarding. Gevolg:
Wanneer de initiële integratie niet goed gebeurt, maakt zich dit blijvend voelbaar in verstoringen, vertragingen en onderlinge verrekeningen. Oplossing:
Intelligent Document Processing (IDP) verbetert het onboardingproces voor nieuwe leveranciers, partners en medewerkers aanzienlijk. IDP automatiseert de extractie van de essentiële gegevens uit documenten als facturen, contracten, urenstaatjes, etc. om die vervolgens op een correcte wijze in de verschillende systemen te verwerken. De technologie speelt snel in op verschillende documentformaten en lay-outs aan zonder handmatige configuraties, wat zorgt voor een naadloze integratie. Resultaat:
Een snelle en correcte “onboarding” van partijen door een foutloze extractie en verwerking van essentiële gegevens. Het vormt een belangrijk deel van de basis voor een productieve onderlinge samenwerking met minder misverstanden, miscommunicatie, foutieve verrekeningen en vertragingen.
Conclusie
De toepassing van Intelligente Documentverwerking (IDP) betekent niet alleen dat u sneller, efficiënter en met minder fouten kunt werken, het maakt een andere manier van werken mogelijk. IDP is een van de bouwstenen van een (meer) autonoom operating model.
De bovenstaande cases representeren slechts een fractie van wat er mogelijk is. Het zijn toepassingen die direct effect hebben. Het zijn ideale toepassingen om meer bekend te worden met de technologie en uw voorstellingsvermogen qua mogelijkheden te vergroten.
Gezien de bredere economische en maatschappelijk ontwikkelingen waar de sector midden in zit, is deze technologie verder te verkennen eigenlijk geen optie meer.
Kunstmatige Intelligentie is hot. We kunnen vrijwel niets meer doen zonder bewust of onbewust in contact te komen met vormen van Kunstmatige Intelligentie. En het wordt steeds belangrijker. Dit artikel is een inleiding tot het vakgebied van de Kunstmatige Intelligentie. Het start met een definitie om vervolgens de verschillende sub-specialismen te verkennen, compleet met omschrijving en enkele toepassingen.
WAT IS KUNSTMATIGE INTELLIGENTIE?
Kunstmatige Intelligentie (KI) maakt gebruik van computers en machines om de vaardigheden van mensen op het gebied van probleemoplossing en besluitvorming te imiteren. Eén van de toonaangevende studieboeken op het vakgebied van KI is Artificial Intelligence: A Modern Approach (link bevindt zich buiten Axisto) van Stuart Russell en Peter Norvig. Daarin werken ze vier mogelijke doelen of definities van KI uit.
Menselijke benadering:
Systemen die denken als mensen
Systemen die zich gedragen als mensen
Rationele benadering:
Systemen die rationeel denken
Systemen die zich rationeel gedragen
Kunstmatige intelligentie speelt onder meer een groeiende rol in (I)IoT (Industrieel) Internet der dingen), waarbij (I)IoT-platformsoftware geïntegreerde AI-mogelijkheden kan bieden.
SUB-SPECIALISMEN BINNEN KUNSTMATIGE INTELLIGENTIE
Er zijn verschillende sub-specialismen die behoren tot het domein van de Kunstmatige Intelligentie. Hoewel er de nodige onderlinge afhankelijkheid tussen veel van deze specialismen zit, heeft elk daarvan unieke eigenschappen die bijdragen aan het overkoepelende thema KI. Het The Intelligent Automation Network (link bevindt buiten Axisto) onderscheidt zeven sub-specialismen, figuur 1.
Figuur 1, Het Intelligent Automation Network onderscheidt zeven sub-specialismen binnen Kunstmatige Intelligentie.
Elke sub-specialisme wordt hieronder verder toegelicht.
MACHINE LEARNING
Machine learning is het vakgebied dat zich richt op het gebruik van gegevens en algoritmen om de manier waarop mensen leren te imiteren met behulp van computers, zonder dat die expliciet geprogrammeerd zijn, en daarbij geleidelijk de nauwkeurigheid te verbeteren. Het artikel “Axisto – een introductie tot Machine Learning” gaat dieper op deze specialiteit in.
MACHINE LEARNING EN PREDICTIVE ANALYTICS
Analytics en machine learning gaan hand in hand. Predictive analytics omvat een verscheidenheid aan statistische technieken, waaronder algoritmen voor machine learning. Met de statistische technieken worden huidige en historische feiten geanalyseerd om voorspellingen te doen over toekomstige of anderszins onbekende gebeurtenissen. Deze voorspellende analysemodellen kunnen in de loop van de tijd worden getraind om te reageren op nieuwe gegevens.
Het bepalende functionele aspect van deze technische benaderingen is dat predictive analytics een voorspellende score (een waarschijnlijkheid) geeft voor elk ‘individu’ (klant, medewerker, zorgpatiënt, product-SKU, voertuig, onderdeel, machine of andere organisatorische eenheid) om te bepalen, te informeren of invloed te hebben op organisatorische processen met betrekking tot grote aantallen ‘individuen’. Toepassingen zijn te vinden bij bijvoorbeeld marketing, kredietrisicobeoordeling, fraudedetectie, productie, gezondheidszorg en overheidsactiviteiten, waaronder wetshandhaving.
In tegenstelling tot andere Business Intelligence (BI)-technologieën is voorspellende analyse toekomstgericht. Gebeurtenissen uit het verleden worden gebruikt om te anticiperen op de toekomst. Vaak is de onbekende gebeurtenis van belang in de toekomst, maar voorspellende analyses kunnen worden toegepast op elk type ‘onbekend’, of het nu in het verleden, het heden of de toekomst is. Bijvoorbeeld het identificeren van verdachten nadat een misdrijf is gepleegd, of creditcardfraude als deze zich voordoet. De kern van voorspellende analyses is gebaseerd op het vastleggen van relaties tussen verklarende variabelen en de voorspelde variabelen uit eerdere gebeurtenissen, en deze te exploiteren om de onbekende uitkomst te voorspellen. Uiteraard hangt de nauwkeurigheid en bruikbaarheid van de resultaten sterk af van het niveau van de gegevensanalyse en de kwaliteit van de aannames.
Machine Learning en voorspellende analyses kunnen een belangrijke bijdrage leveren aan elke organisatie, maar invoering zonder na te denken over hoe ze in de dagelijkse activiteiten passen zal hun vermogen om relevante inzichten te leveren sterk beperken.
Om waarde uit voorspellende analyses en machine learning te halen, moet niet alleen de architectuur aanwezig zijn om deze oplossingen te ondersteunen. Ook hoogwaardige gegevens moeten beschikbaar zijn om ze te voeden en te helpen leren. Gegevensvoorbereiding en -kwaliteit zijn belangrijke factoren voor voorspellende analyses. Invoergegevens kunnen meerdere platforms omvatten en meerdere big data-bronnen bevatten. Om bruikbaar te zijn, moeten deze gecentraliseerd, uniform en in een coherent formaat zijn.
Daartoe moeten organisaties een degelijke aanpak ontwikkelen om gegevensbeheer te bewaken en ervoor te zorgen dat alleen gegevens van hoge kwaliteit worden vastgelegd en opgeslagen. Verder moeten bestaande processen worden aangepast om voorspellende analyses en machine learning op te nemen, omdat dit organisaties in staat zal stellen de efficiëntie op elk punt in het bedrijf te verbeteren. Ten slotte moeten zij weten welke problemen ze willen oplossen, dit om het beste en meest toepasselijke model te bepalen.
NATURAL LANGUAGE PROCESSING (NLP)
Natuurlijke taalverwerking is het vermogen van een computerprogramma om menselijke taal te begrijpen zoals deze wordt gesproken en geschreven – ook wel natuurlijke taal genoemd. NLP is een manier voor computers om betekenis uit menselijke taal te analyseren en te extraheren, zodat ze taken als vertaling, sentimentanalyse en spraakherkenning kunnen uitvoeren.
Dit is moeilijk, omdat het veel ongestructureerde gegevens omvat. De stijl waarin mensen praten en schrijven (ook wel stemgeluid/ toon genoemd) is uniek voor individuen en evolueert voortdurend om populair taalgebruik te weerspiegelen. Het begrijpen van de context is ook een probleem – iets dat semantische analyse vraagt van machine learning. Natuurlijk taalbegrip (NLU) is een vertakking van NLP en pikt deze nuances op via machinaal ‘begrijpend lezen’ in plaats van simpelweg de letterlijke betekenissen te begrijpen. Het doel van NLP en NLU is om computers te helpen menselijke taal goed genoeg te begrijpen, zodat ze op een natuurlijke manier kunnen converseren.
Al deze functies worden beter naarmate we meer schrijven, spreken en praten met computers: ze leren voortdurend. Een goed voorbeeld van dit iteratief leren is een functie als Google Translate die gebruikmaakt van een systeem dat Google Neural Machine Translation (GNMT) wordt genoemd. GNMT is een systeem dat werkt met een groot kunstmatig neuraal netwerk om steeds vloeiender en nauwkeuriger te vertalen. In plaats van één stuk tekst tegelijk te vertalen, probeert GNMT hele zinnen te vertalen. Omdat het miljoenen voorbeelden doorzoekt, gebruikt GNMT een bredere context om de meest relevante vertaling af te leiden.
Het onderstaande is een selectie van taken in natuurlijke taalverwerking (NLP). Sommige van deze taken hebben directe toepassingen in de echte wereld, terwijl andere vaker dienen als sub-taken die worden gebruikt om grotere taken op te lossen.
Optical Character Recognition (OCR)
Bepalen van de tekst die hoort bij een gegeven afbeelding die gedrukte tekst vertegenwoordigt.
Spraakherkenning
Aan de hand van een geluidsfragment van een sprekende persoon of personen bepalen wat de tekstuele representatie van de toespraak is. Dit is het tegenovergestelde van tekst naar spraak en is een extreem moeilijk probleem. In natuurlijke spraak zijn er nauwelijks pauzes tussen opeenvolgende woorden, en dus is spraaksegmentatie een noodzakelijke sub-taak van spraakherkenning (zie ‘woordsegmentatie hieronder). In de meeste gesproken talen gaan de klanken die opeenvolgende letters vertegenwoordigen in elkaar over in een proces dat co-articulatie wordt genoemd. De conversie van het analoge signaal naar discrete karakters kan dus een zeer moeilijk proces zijn. Aangezien woorden in dezelfde taal worden gesproken door mensen met verschillende accenten, moet de spraakherkenningssoftware ook nog een grote verscheidenheid aan invoer kunnen herkennen als identiek aan elkaar in termen van tekstueel equivalent.
Tekst naar Spraak
De elementen van een gegeven een tekst worden getransformeerd en een gesproken representatie wordt geproduceerd. Tekst-naar-spraak kan worden gebruikt om slechtzienden te helpen.
Woord segmentatie (Tokenization)
Opsplitsen van een stuk doorlopende tekst in afzonderlijke woorden. Voor een taal als Engels is dit vrij triviaal, aangezien woorden meestal worden gescheiden door spaties. Sommige geschreven talen, zoals Chinees, Japans en Thais, markeren woordgrenzen echter niet op een dergelijke manier, en in die talen is tekstsegmentatie een belangrijke taak die kennis van de woordenschat en morfologie van woorden in de taal vereist. Soms wordt woordsegmentatie ook toegepast in bijvoorbeeld het maken van woorden in datamining.
Document AI
Een Document AI-platform zit bovenop de NLP-technologie, waardoor gebruikers zonder eerdere ervaring met kunstmatige intelligentie, machine learning of NLP een computer snel kunnen trainen om de specifieke gegevens die ze nodig hebben uit verschillende documenttypen te halen. NLP-aangedreven Document AI stelt niet-technische teams in staat om snel toegang te krijgen tot informatie die verborgen is in documenten, bijvoorbeeld advocaten, bedrijfsanalisten en accountants.
Grammaticale fout detectie en correctie
Grammaticale fout detectie en correctie brengt een grote bandbreedte van problemen met zich mee op alle niveaus van taalkundige analyse (fonologie/orthografie, morfologie, syntaxis, semantiek, pragmatiek). Grammaticale fout correctie is van grote invloed omdat het honderden miljoenen mensen raakt die een tweede taal gebruiken of zich eigen maken. Voor wat betreft spelling, morfologie, syntaxis en bepaalde aspecten van semantiek kan dit, door de ontwikkeling van krachtige neurale taalmodellen zoals GPT-2, sinds 2019 worden beschouwd als een grotendeels opgelost probleem. Verschillende commerciële toepassingen zijn op de markt verkrijgbaar.
Machine vertaling
Automatisch tekst vertalen van de ene menselijke taal naar de andere is één van de moeilijkste problemen: alle verschillende soorten kennis zijn vereist om dit goed te doen, zoals grammatica, semantiek, feiten over de echte wereld, enz..
Natural Language Generation (NLG)
Informatie omzetten uit computerdatabases of semantische intentie in leesbare menselijke taal.
Natural Language Understanding (NLU)
NLU betreft het begrip van menselijke taal, zoals Nederlands, Engels en Frans, waarmee computers opdrachten kunnen begrijpen zonder de geformaliseerde syntaxis van computertalen. NLU stelt computers ook in staat om terug te communiceren met mensen in hun eigen taal. Het belangrijkste doel van NLU is om chat- en spraak gestuurde bots te maken die zonder toezicht met het publiek kunnen communiceren. Vragen beantwoorden en het antwoord op een vraag in mensentaal bepalen. Typische vragen hebben een specifiek juist antwoord, zoals “Wat is de hoofdstad van Finland?”, maar soms worden ook open vragen overwogen (zoals “Wat is de zin van het leven?”). Hoe werkt het begrijpen van natuurlijke taal? NLU analyseert gegevens om de betekenis ervan te bepalen door algoritmen te gebruiken om menselijke spraak te reduceren tot een gestructureerde ontologie – een gegevensmodel dat bestaat uit semantiek en pragmatische definities. Twee fundamentele concepten van NLU zijn intentie en entiteitsherkenning. Intentieherkenning is het proces van het identificeren van het gebruikerssentiment in invoertekst en het bepalen van het doel. Dit is het eerste en belangrijkste onderdeel van NLU omdat het de betekenis van de tekst vastlegt. Entiteitsherkenning is een specifiek type NLU dat zich richt op het identificeren van de entiteiten in een bericht en het vervolgens extraheren van de belangrijkste informatie over die entiteiten. Er zijn twee soorten entiteiten: benoemde entiteiten en numerieke entiteiten. Benoemde entiteiten zijn gegroepeerd in categorieën, zoals mensen, bedrijven en locaties. Numerieke entiteiten worden herkend als getallen, valuta en percentages.
Tekst-naar-beeld generatie
Geven van een beschrijving van een afbeelding en genereer een afbeelding die overeenkomt met de beschrijving.
Natuurlijke taalverwerking – mensen begrijpen – is de sleutel tot AI om zijn claim op intelligentie te rechtvaardigen. Nieuwe deep learning-modellen verbeteren voortdurend de prestaties van AI in Turing-tests. Google’s Director of Engineering Ray Kurzweil voorspelt dat “AI’s tegen 2029 “menselijke niveaus van intelligentie zullen bereiken“(link bevindt zich buiten Axisto).
Overigens, wat mensen zeggen is soms heel wat anders dan wat mensen doen. Begrijpen van de menselijke natuur is bepaald niet eenvoudig. Intelligentere AI’s vergroten het perspectief van kunstmatig bewustzijn, waardoor een nieuw veld van filosofisch en toegepast onderzoek is ontstaan.
SPRAAK
Spraakherkenning staat ook bekend als automatische spraakherkenning (ASR), computerspraakherkenning of spraak-naar-tekst. Het is een mogelijkheid die natuurlijke taalverwerking (NLP) gebruikt om menselijke spraak in een geschreven formaat te verwerken. Veel mobiele apparaten nemen spraakherkenning in hun systemen op om gesproken zoekopdrachten uit te voeren, bijv. Siri van Apple.
Een belangrijk spraakgebied in AI is spraak naar tekst, het proces waarbij audio en spraak worden omgezet in geschreven tekst. Het kan gebruikers met een visuele of fysieke beperking helpen en kan de veiligheid bevorderen met handsfree bediening. Spraak-naar-teksttaken bevatten machine learning-algoritmen die leren van grote datasets van menselijke stemvoorbeelden om tot voldoende gebruikskwaliteit te komen. Spraak-naar-tekst heeft waarde voor bedrijven omdat het kan helpen bij de transcriptie van video- of telefoongesprekken. Tekst naar spraak zet geschreven tekst om in audio die klinkt als natuurlijke spraak. Deze technologieën kunnen worden gebruikt om personen met een spraakstoornis te helpen. Polly van Amazon is een voorbeeld van een technologie die deep learning gebruikt om spraak te synthetiseren die menselijk klinkt ten behoeve van bijvoorbeeld e-learning en telefonie.
Spraakherkenning is een taak waarbij spraak door een systeem wordt ontvangen via een microfoon en wordt gecontroleerd aan de hand van een database met een grote woordenschat voor patroonherkenning. Wanneer een woord of zin wordt herkend, zal deze reageren met de bijbehorende verbale reactie of een specifieke taak. Voorbeelden van spraakherkenning zijn Apple’s Siri, Amazon’s Alexa, Microsoft’s Cortana en Google’s Google Assistant. Deze producten moeten de spraakinvoer van een gebruiker kunnen herkennen en de juiste spraakuitvoer of actie kunnen toewijzen. Nog geavanceerder zijn pogingen om spraak te creëren op basis van hersengolven voor degenen die niet kunnen spreken of mogelijkheid tot spraak hebben verloren.
EXPERTSYSTEMEN
Een expertsysteem gebruikt een kennisbank over zijn toepassingsdomein en een inferentie-engine om problemen op te lossen die normaal gesproken menselijke intelligentie vereisen. Een interferentie engine is een onderdeel van het systeem dat logische regels toepast op de kennisbank om nieuwe informatie af te leiden. Voorbeelden van expertsystemen zijn onder meer financieel beheer, bedrijfsplanning, kredietautorisatie, ontwerp van computerinstallaties en planning van luchtvaartmaatschappijen. Een expertsysteem op het gebied van verkeersbeheer kan bijvoorbeeld helpen bij het ontwerpen van slimme steden door op te treden als een “menselijke operator” voor het doorgeven van verkeersfeedback voor de juiste routes.
Een beperking van expertsystemen is dat ze het gezond verstand missen dat mensen wel hebben, zoals een begrip van de grenzen van hun vaardigheden en hoe hun aanbevelingen in het grotere geheel passen. Ze missen het zelfbewustzijn van mensen. Expertsystemen zijn geen vervanging voor besluitvormers omdat ze geen menselijke capaciteiten hebben, maar ze kunnen het menselijke werk dat nodig is om een probleem op te lossen drastisch verlichten.
PLANNING SCHEDULING EN OPTIMALISITIE
KI-planning is de taak om te bepalen hoe een systeem zijn doelen op de beste manier kan bereiken. Het is het kiezen van opeenvolgende acties die een grote kans hebben om de toestand van de omgeving stapsgewijs te veranderen ten einde een doel te bereiken. Dit soort oplossingen is vaak complex. In dynamische omgevingen met constante verandering, vereisen ze frequente trial-and-error iteratie om te finetunen.
Plannen is het maken van planningen, of tijdelijke toewijzingen van activiteiten aan resources, rekening houdend met doelen en beperkingen. Om een algortime te ontwerpen bepaalt planning de volgorde en timing van acties die door het algoritme worden gegenereerd. Deze worden doorgaans uitgevoerd door intelligente uitvoerders, autonome robots en onbemande voertuigen. Wanneer ze goed zijn ontworpen kunnen ze planningsproblemen voor organisaties op een kostenefficiënte manier oplossen. Optimalisatie kan worden bereikt door een van de meest populaire ML- en Deep Learning-optimalisatiestrategieën te gebruiken: gradient descent. Dit wordt gebruikt om een machine learning-model te trainen door de parameters ervan op een iteratieve manier te wijzigen om een bepaalde functie tot het lokale minimum te minimaliseren.
Kunstmatige intelligentie bevindt zich aan de ene kant van het spectrum van intelligente automatisering, terwijl Robotic Process Automation (RPA), softwarerobots die menselijke acties nabootsen, aan de andere kant staat. De ene houdt zich bezig met het repliceren van hoe mensen denken en leren, terwijl de andere zich bezighoudt met het repliceren van hoe mensen dingen doen. Robotica ontwikkelt complexe sensor motorische functies die machines in staat stellen zich aan te passen aan hun omgeving. Robots kunnen de omgeving voelen met behulp van computervisie.
Het belangrijkste idee van robotica is om robots zo autonoom mogelijk te maken door te leren. Ondanks het niet bereiken van mensachtige intelligentie, zijn er nog steeds veel succesvolle voorbeelden van robots die autonome taken uitvoeren, zoals dozen dragen, objecten oppakken en neerleggen. Sommige robots kunnen besluitvorming leren door een verband te leggen tussen een actie en een gewenst resultaat. Kismet, een robot bij het Artificial Intelligence Lab van het M.I.T., leert zowel lichaamstaal als stem te herkennen en gepast te reageren. Deze MIT video (link staat buiten Axisto) geeft een goede indruk.
COMPUTER VISION
Computervisie is een gebied van AI dat computers traint om informatie uit beeld- en videogegevens vast te leggen en te interpreteren. Door machine learning (ML)-modellen toe te passen op afbeeldingen, kunnen computers objecten classificeren en reageren, zoals gezichtsherkenning om een smartphone te ontgrendelen of beoogde acties goed te keuren. Wanneer computervisie wordt gekoppeld aan Deep Learning, combineert het het beste van twee werelden: geoptimaliseerde prestaties gecombineerd met nauwkeurigheid en veelzijdigheid. Deep Learning biedt IoT-ontwikkelaars een grotere nauwkeurigheid bij objectclassificatie.
Machine vision gaat nog een stap verder door computer vision-algoritmen te combineren met beeldregistratiesystemen om robots beter aan te sturen. Een voorbeeld van computervisie is een computer die een unieke reeks strepen op een universele productcode kan ‘zien’ en deze kan scannen en herkennen als een unieke identificatiecode. Optical Character Recognition (OCR) maakt gebruik van beeldherkenning van letters om papieren gedrukte records en/of handschrift te ontcijferen, ondanks het grote aantal verschillende lettertypen en handschriftvariaties.
WAT IS MACHINE LEARNING?
Dit artikel behandelt de introductie tot machine learning en de direct gerelateerde concepten.
Machine learning is het vakgebied dat computers de mogelijkheid geeft om te leren zonder expliciet geprogrammeerd te zijn. Het is een subset van kunstmatige intelligentie (KI) die zich richt op het gebruik van gegevens en algoritmen om de manier waarop mensen leren te imiteren en waarbij de nauwkeurigheid geleidelijk wordt verbeterd.
Het basisconcept van machine learning betreft het gebruik van statistische leer- en optimalisatiemethoden (link bevindt zich buiten Axisto) waarmee computers datasets kunnen analyseren en identificeren. Machine learning-technieken maken gebruik van datamining om historische trends te identificeren teneinde toekomstige modellen te informeren.
Volgens de University of California, Berkeley, bestaat het typische begeleide machine learning-algoritme uit (ongeveer) drie componenten:
Een beslissingsproces: Een combinatie van berekeningen of andere stappen die de gegevens opnemen en een ‘gok’ retourneren van het soort patroon in de gegevens dat het algoritme zoekt.
Een foutfunctie: Een methode om te meten hoe goed de gok was door deze te vergelijken met bekende voorbeelden (indien beschikbaar). Is het besluitvormingsproces goed verlopen? Zo niet, hoe kwantificeert u “hoe erg” de misser was?
Een update- of optimalisatieproces: waarbij het algoritme naar de misser kijkt en vervolgens de manier, waarop het besluitvormingsproces tot de uiteindelijke beslissing komt, bijwerkt zodat de volgende keer de misser niet zo groot zal zijn.
Machine learning is een belangrijk onderdeel van het groeiende veld van datawetenschappen. Met statistische methoden worden algoritmen getraind om classificaties of voorspellingen te doen, waardoor belangrijke inzichten uit gegevens worden gehaald.
HOE LEERT EEN MACHINE LEARNING ALGORITME?
De technologiefirma Nvidia (link bevindt zich buiten Axisto) onderscheidt vier leermodellen, die worden bepaald door het niveau van menselijke interventie:
Begeleid leren: Als je onder begeleiding een taak leert, is er iemand aanwezig die beoordeelt of je het juiste antwoord krijgt. Evenzo betekent dit bij begeleid leren dat je een volledige set gelabelde(*) gegevens hebt, terwijl je een algoritme traint.
Onbegeleid leren: Bij onbegeleid leren krijgt een ‘deep learning’-model een dataset aangereikt zonder expliciete instructies over wat ermee te doen. De trainingsdataset is een verzameling voorbeelden zonder een specifiek gewenst resultaat of correct antwoord. Het neurale netwerk probeert vervolgens automatisch structuur in de gegevens te vinden door nuttige functies te extraheren en de structuur ervan te analyseren.
Semi-begeleid leren: is voor het grootste deel precies hoe het klinkt: een trainingsdataset met zowel gelabelde als niet-gelabelde data. Deze methode is met name handig wanneer het moeilijk is om relevante kenmerken uit de gegevens te extraheren en het labelen van voorbeelden een tijdrovende taak is voor de experts.
Versterkend leren: Bij dit soort machine learning proberen AI-algoritmes de optimale manier te vinden om een bepaald doel te bereiken of de prestaties van een specifieke taak te verbeteren. Als het algoritme actie onderneemt die in de richting van het doel gaat, ontvangt het een beloning. Het algemene doel: voorspel de beste volgende stap om de grootste uiteindelijke beloning te verdienen. Om zijn keuzes te maken, vertrouwt het algoritme zowel op lessen uit eerdere feedback als op verkenning van nieuwe tactieken die een grotere beloning kunnen opleveren. Het gaat om een langdurige strategie — net zoals de beste directe zet in een schaakspel je uiteindelijk niet kan helpen om te winnen; het algoritme probeert de cumulatieve beloning te maximaliseren. Het is een iteratief proces: hoe meer feedbackrondes, hoe beter de strategie van het algoritme wordt. Deze techniek is vooral handig voor het trainen van robots, die een reeks beslissingen nemen in taken zoals het besturen van een autonoom voertuig of het beheren van voorraad in een magazijn.
* Volledig gelabeld betekent dat elk voorbeeld in de trainingsdataset is voorzien is van het antwoord dat het algoritme op zichzelf zou moeten produceren. Dus een gelabelde dataset van bloemenafbeeldingen zou het model vertellen welke foto’s rozen, madeliefjes en narcissen waren. Wanneer een nieuwe afbeelding wordt getoond, vergelijkt het model deze met de trainingsvoorbeelden om het juiste label te voorspellen.
In alle vier de leermodellen leert het algoritme van datasets met menselijke regels of kennis.
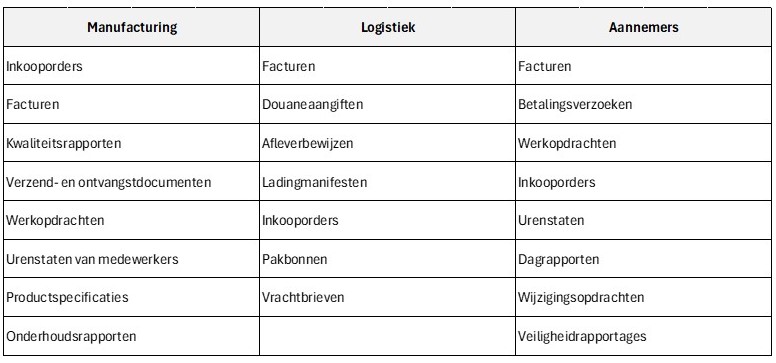
Bij het navigatie van het domein van kunstmatige intelligentie komt niet alleen de term machine learning langs, maar ook deep learning (DL) en neurale netwerken (artificiële neurale netwerken – ANN). Kunstmatige intelligentie en machine learning worden door elkaar heen gebruikt, netals machine learning en deep learning. Maar in feite zijn ze een subset van een subset zoals gevisualiseerd in figuur 1.
Figuur 1. Kunstmatige neurale netwerken zijn een subset van deep learning is een subset van machine learning is een subset van kunstmatige intelligentie.
Daarom worden hieronder ook deep learning en kunstmatige neurale netwerken kort toegelicht.
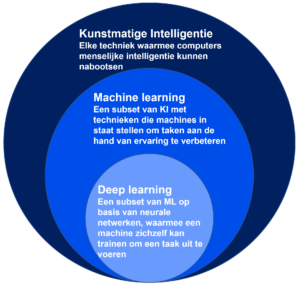
HET VERSCHIL TUSSEN MACHINE LEARNING EN DEEP LEARNING IS IN DE MANIER WAAROP EEN ALGORITME LEERT
In tegenstelling tot machine learning, vereist deep learning geen menselijke tussenkomst om gegevens te verwerken. Deep learning automatiseert een groot deel van het functie-extractie proces, waardoor een deel van de handmatige menselijke interventie, wordt geëlimineerd en het gebruik van grotere datasets mogelijk wordt. “Non-deep” machine learning is voor het leren in meer of mindere mate afhankelijk van menselijk ingrijpen. Menselijke experts bepalen de reeks functies om de verschillen in de gegevensinvoer te begrijpen, waarvoor meestal meer gestructureerde gegevens nodig zijn om te leren. “Deep” machine learning kan gebruikmaken van gelabelde datasets, ook wel begeleid leren genoemd, om het algoritme te informeren, maar het vereist niet per se een gelabelde dataset. Het kan ook ongestructureerde gegevens in onbewerkte vorm verwerken (bijv. tekst en afbeeldingen) en het kan automatisch de reeks functies bepalen die verschillende categorieën van gegevens van elkaar onderscheiden.
Figuur 2. Het verschil tussen Machine Learning en Deep Learning gevisualiseerd.
Deep learning gebruikt meerdere lagen om geleidelijk hogere niveaus van functies uit de onbewerkte invoer te extraheren. Bij beeldverwerking kunnen lagere lagen bijvoorbeeld randen identificeren, terwijl hogere lagen de concepten kunnen identificeren die relevant zijn voor een mens, zoals cijfers of letters of gezichten.
Bij deep learning leert elke laag zijn invoergegevens om te zetten in een iets meer abstracte en samengestelde weergave. In een toepassing voor beeldherkenning kan de onbewerkte invoer een matrix van pixels zijn. De eerste representatieve laag kan de pixels abstraheren en randen coderen. De tweede laag kan rangschikkingen van randen samenstellen en coderen en de derde laag kan een neus en ogen coderen. De vierde laag kan herkennen dat de afbeelding een gezicht bevat. Belangrijk is dat een deep learning proces zelfstandig kan leren welke kenmerken op welk niveau optimaal kunnen worden geplaatst. Dit elimineert de noodzaak voor handmatig ingrijpen niet volledig; verschillende aantallen lagen en laagafmetingen kunnen bijvoorbeeld verschillende gradaties van abstractie opleveren.
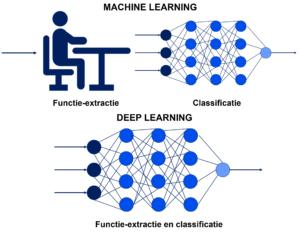
Het woord “deep” in “deep learning” verwijst naar het aantal lagen waardoor de data wordt getransformeerd, zie figuur 3.
NEURALE NETWERKEN
Kunstmatige neurale netwerken leren op meerdere lagen van details of representaties van gegevens. Door deze verschillende lagen gaat informatie van parameters op een laag niveau naar parameters op een hoger niveau. Deze verschillende niveaus corresponderen met verschillende niveaus van data-abstractie, wat leidt tot leren en herkennen.
Een ANN is gebaseerd op een verzameling van verbonden eenheden die kunstmatige neuronen worden genoemd (analoog aan biologische neuronen in een biologisch brein). Elke verbinding (synaps) tussen neuronen kan een signaal naar een ander neuron sturen. Het ontvangende (post-synaptische) neuron kan het signaal/de signalen verwerken en vervolgens de stroom-afwaartse neuronen die ermee verbonden zijn, signaleren. Neuronen kunnen een toestand hebben, over het algemeen weergegeven door reële getallen, meestal tussen 0 en 1. Neuronen en synapsen kunnen ook een gewicht hebben dat varieert naarmate het leren vordert, wat de sterkte van het signaal dat het stroomafwaarts verzendt, kan vergroten of verkleinen. Meestal zijn neuronen georganiseerd in lagen. Verschillende lagen kunnen verschillende soorten transformaties uitvoeren op hun invoer. Signalen gaan van de eerste (invoer) naar de laatste (uitvoer) laag, mogelijk na meerdere keren door de lagen heen te zijn gegaan.
Figuur 3. Lagen in een kunstmatig neuraal netwerk.
TOEPASSINGEN VAN MACHINE LEARNING
Er zijn veel toepassingen voor machine learning; het is een van de drie belangrijkste elementen van Intelligente Automatisering en een autonoom operating model binnen Industrie 4.0. Machine Learning-applicaties kunnen tekst lezen en bepalen of de persoon die het heeft geschreven een klacht indient of feliciteert. Ze kunnen ook naar een muziekstuk luisteren, beslissen of het iemand blij of verdrietig zal maken, en andere muziekstukken zoeken die bij de stemming passen. In sommige gevallen kunnen ze zelfs hun eigen muziek componeren waarin dezelfde thema’s tot uitdrukking komen, of waarvan ze weten dat ze gewaardeerd zullen worden door de fans van het originele stuk.
Neurale netwerken worden gebruikt voor een verscheidenheid aan taken, waaronder computervisie, spraakherkenning, machinevertaling, filtering van sociale netwerken, het spelen van bord- en videogames en medische diagnose. Vanaf 2017 hebben neurale netwerken doorgaans een paar duizend tot een paar miljoen eenheden en miljoenen verbindingen. Ondanks dat dit aantal enkele ordes van grootte kleiner is dan het aantal neuronen in een menselijk brein, kunnen deze netwerken veel taken uitvoeren op een niveau dat verder gaat dan dat van mensen (bijvoorbeeld gezichten herkennen en “Go” spelen).